 Catalogue PIGMA
Catalogue PIGMA
2023
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
Resolution
-

'''DEFINITION''' The omi_climate_sst_ibi_area_averaged_anomalies product for 2024 includes Sea Surface Temperature (SST) anomalies, given as monthly mean time series starting on 1982 and averaged over the IBI areas. The IBI SST OMI is built from the CMEMS Reprocessed European North West Shelf Iberai-Biscay-Irish areas (SST_MED_SST_L4_REP_OBSERVATIONS_010_026, see e.g. the OMI QUID, http://marine.copernicus.eu/documents/QUID/CMEMS-OMI-QUID-CLIMATE-SST- IBI_v3.pdf), which provided the SSTs used to compute the evolution of SST anomalies over the IBI areas. This reprocessed product consists of daily (nighttime) interpolated 0.05° grid resolution SST maps over the European North West Shelf Iberai-Biscay-Irish areas built from re-processed ESA SST CCI, C3S (Embury et al., 2019). Anomalies are computed against the 1991-2020 reference period. The reference for this OMI can be found in the first and second issue of the Copernicus Marine Service Ocean State Report (OSR), Section 1.1 (Roquet et al., 2016; Mulet et al., 2018). '''CONTEXT''' Sea surface temperature (SST) is a key climate variable since it deeply contributes in regulating climate and its variability (Deser et al., 2010). SST is then essential to monitor and characterise the state of the global climate system (GCOS 2010). Long-term SST variability, from interannual to (multi-)decadal timescales, provides insight into the slow variations/changes in SST, i.e. the temperature trend (e.g., Pezzulli et al., 2005). In addition, on shorter timescales, SST anomalies become an essential indicator for extreme events, as e.g. marine heatwaves (Hobday et al., 2018). '''CMEMS KEY FINDINGS ''' The overall trend in the SST anomalies in this region is 0.012 ±0.002 °C/year over the period 1982-2024. '''DOI (product):''' https://doi.org/10.48670/moi-00256
-
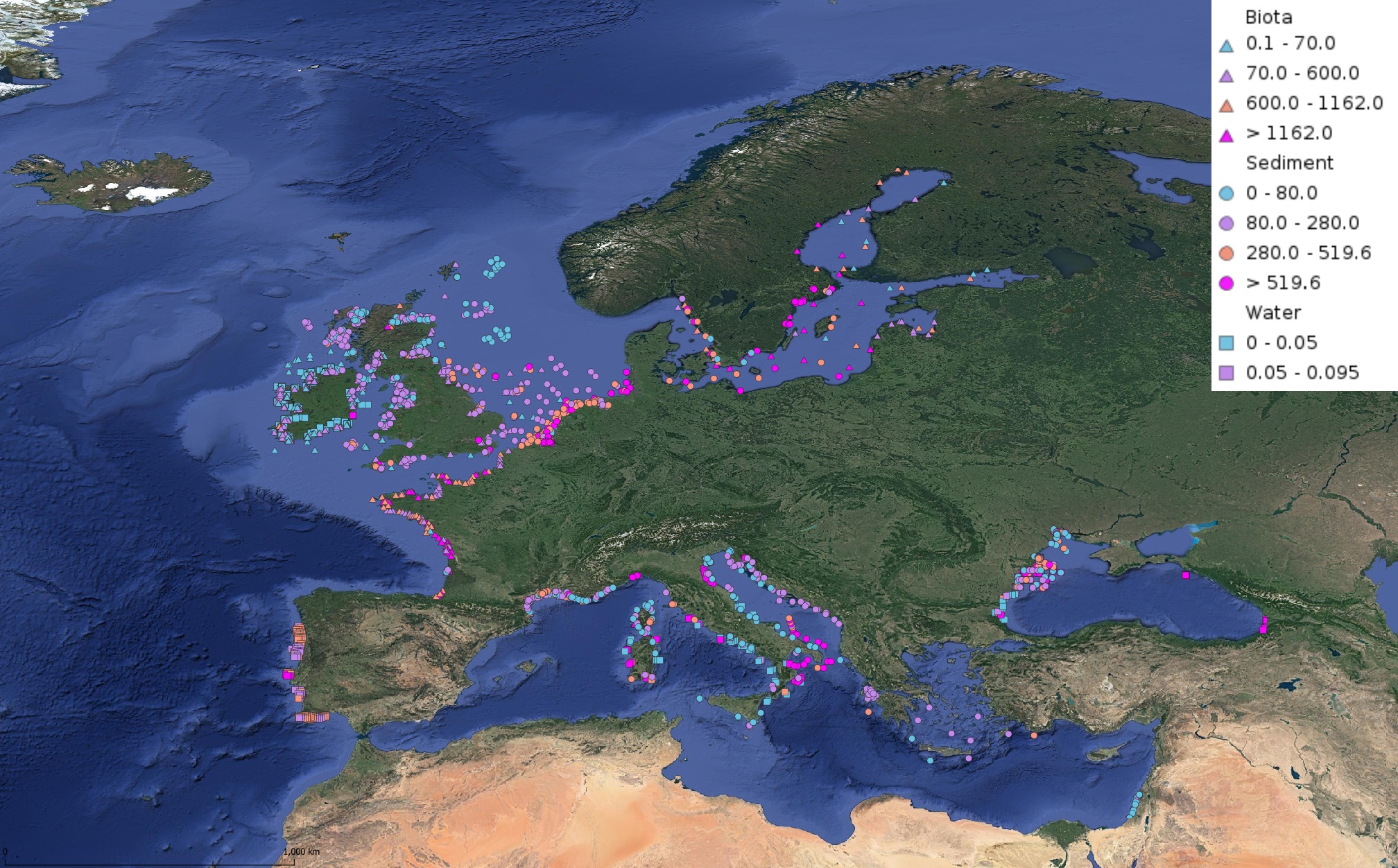
This product displays for Cadmium, median values of the last 6 available years that have been measured per matrix and are present in EMODnet regional contaminants aggregated datasets, v2022. The median values ranges are derived from the following percentiles: 0-25%, 25-75%, 75-90%, >90%. Only "good data" are used, namely data with Quality Flag=1, 2, 6, Q (SeaDataNet Quality Flag schema). For water, only surface values are used (0-15 m), for sediment and biota data at all depths are used.
-
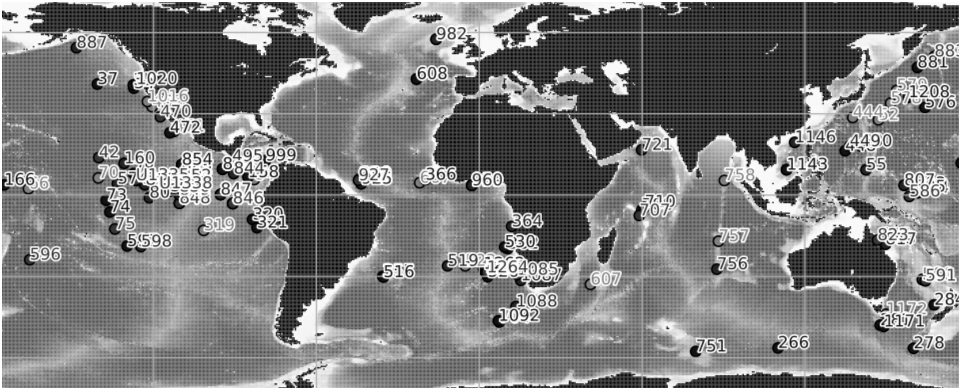
Compilation of published ocean drilling (DSDP, ODP and IODP) records of sedimentation rates, CaCO3, opal and terrigenous accumulation rates that cover the late Miocene and early Pliocene interval. We compiled oceanographic data from DSDP, ODP and IODP expeditions that cover the late Miocene and early Pliocene. Data mining was performed by automatically collecting the Pangaea datasets that correspond to the selected time interval and that have at least one of the following variables: sedimentation rate, dry bulk density, mass accumulation rate (MAR), CaCO3 accumulation rate, bSiO2 accumulation rate (biogenic SiO2) , %CaCO3, %bSiO2. The compilation was then improved by manually adding datasets absent from Pangaea but relevant to our study. The data compilation contains 154 datasets (122 are from Pangaea) from 118 different ocean drilling sites. Age-depth models have been calibrated to the GTS2020 time scale in order to perform a temporal comparison of the datasets. This step was performed using the Neptune Sandbox Berlin database (Renaudie et al. 2020, Palaeontologia Electronica, DOI:10.26879/1032). The Meta_Data_Table file is a metadata table with the following information : site number, dataset label, site label, publication, elevation, site coordinates, site paleocoordinates (10 Ma), available variables, variables used for labeling, the time scale used in the original publication, and the web link to the original dataset. The Time_series file is a file that contains the time series of all the variables in all the data sets in this repository. Each file (.csv) contains a dataset and includes the following information: - Site number - Original link of the dataset - Citation - List of ages - List of values for each variable
-

This dataset comprises the global frequency, classification and distribution of marine heat waves (MHWs) from 1996-2020, in Chauhan et al. 2023 (https://doi.org/10.3389/fmars.2023.1177571). The classification was done based on their attributes and using different baselines. Daily SST values were extracted from the NOAA-OISST v2 high-resolution (0.25°) dataset from 1982-2020. MHWs were detected using the method presented by Hobday et al. 2016 (https://doi.org/10.1016/j.pocean.2015.12.014), and by using the 95th percentile of the accumulated temperature distribution to flag the extreme events. A shifting baseline of 8-year rolling period was selected between the years 1982-1996, since this period shows relatively stable maximum values of temperature across different ocean regions. The shifting baseline aims to account for the decadal changes of westerly winds, temperatures and ocean gyres circulations. The classification was done using the KMeans clustering algorithm to identify the relevant features of MHWs and classify them into separate groups based on feature similarities. This algorithm takes MHW features, namely duration, maximum intensity, rate onset and rate decline, as input vectors and applies clustering in the 4-dimensional feature space where each data point represents an MHW event. Note that all the MHWs features are standardized because unequal variances can put more weight on variables with smaller variances. This record comprehends the geospatial datasets of: Average number of MHW days per year (i.e., the sum of all MHW days divided by the total number of years, 1996-2020). Average cumulative intensity per year (i.e., the sum of cumulative intensity divided by the total number of years, 1996-2020). Total number of MHW events across the different periods averaged on the total number of years (1989-2020). The period 1982-1988 was only used as an initial baseline without calculating MHWs. Spatial distribution of three MHW categories: moderate MHWs, abrupt and Intense MHWs and extreme MHWs; displaying the total number of MHW days normalized by the number of years considered (i.e., 1989-2020). Distribution of Extreme MHWs across the different periods (A) 1989-1996, (B) 1997-2004, (C) 2005-2012, (D) 2013-2020. The relative frequency (γ) is a ratio of extreme MHWs in a specific period and all extreme MHWs in the same cluster for all periods.
-
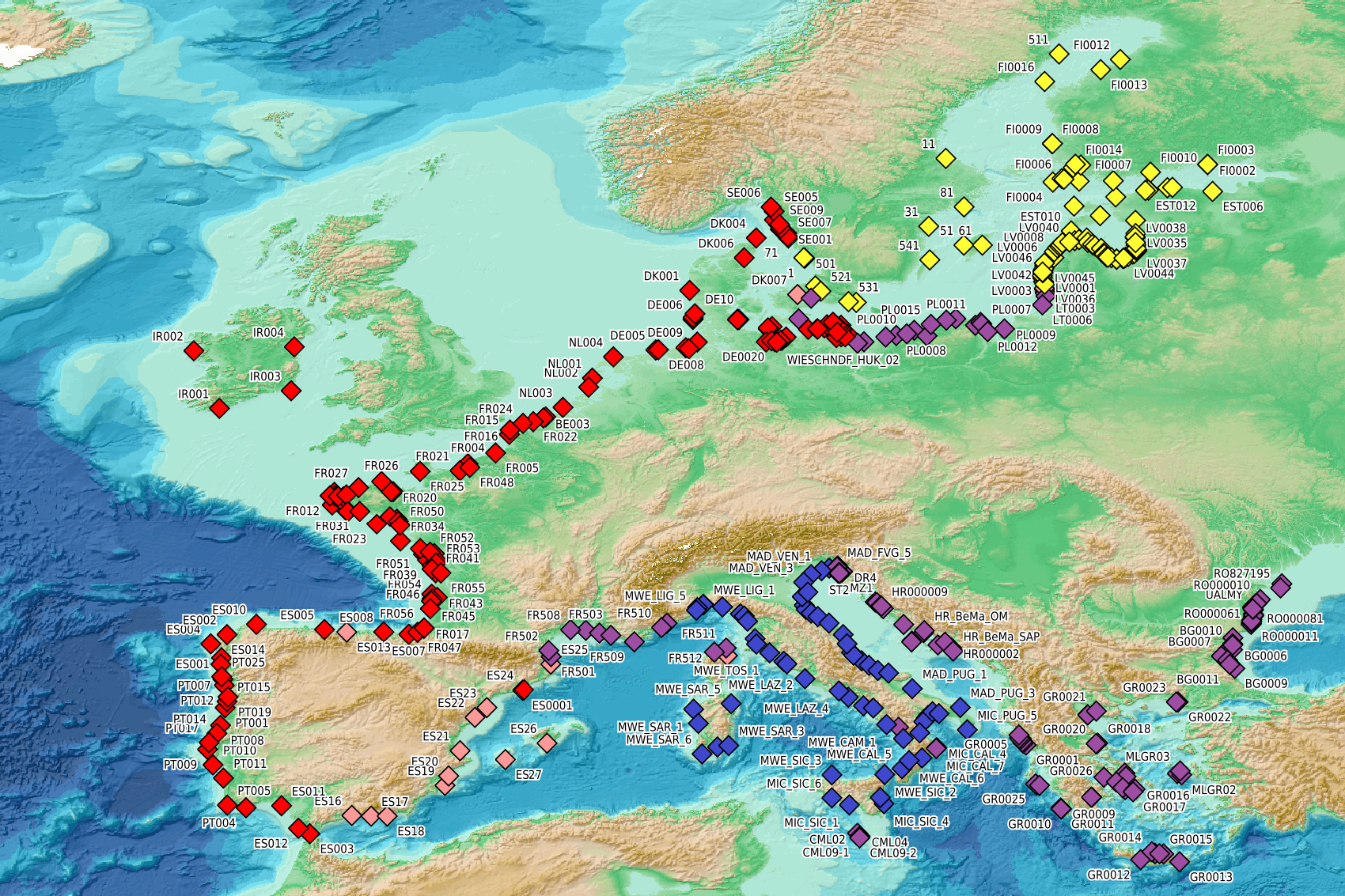
This visualization product displays beaches locations where the Marine Strategy Framework Directive (MSFD) monitoring protocol has been applied to collate data on macrolitter (> 2.5 cm). Reference lists associated with these protocols have been indicated with different colors in the map. EMODnet Chemistry included the collection of marine litter in its 3rd phase. Since the beginning of 2018, data of beach litter have been gathered and processed in the EMODnet Chemistry Marine Litter Database (MLDB). The harmonization of all the data has been the most challenging task considering the heterogeneity of the data sources, sampling protocols and reference lists used on a European scale. Preliminary processing were necessary to harmonize all the data: - Exclusion of OSPAR 1000 protocol: in order to follow the approach of OSPAR that it is not including these data anymore in the monitoring; - Selection of MSFD surveys only (exclusion of other monitoring, cleaning and research operations); - Exclusion of beaches without coordinates; - Some categories & some litter types like organic litter, small fragments (paraffin and wax; items > 2.5cm) and pollutants have been removed. The list of selected items is attached to this metadata. This list was created using EU Marine Beach Litter Baselines and EU Threshold Value for Macro Litter on Coastlines from JRC (these two documents are attached to this metadata). More information is available in the attached documents. Warning: the absence of data on the map doesn't necessarily mean that they don't exist, but that no information has been entered in the Marine Litter Database for this area.
-
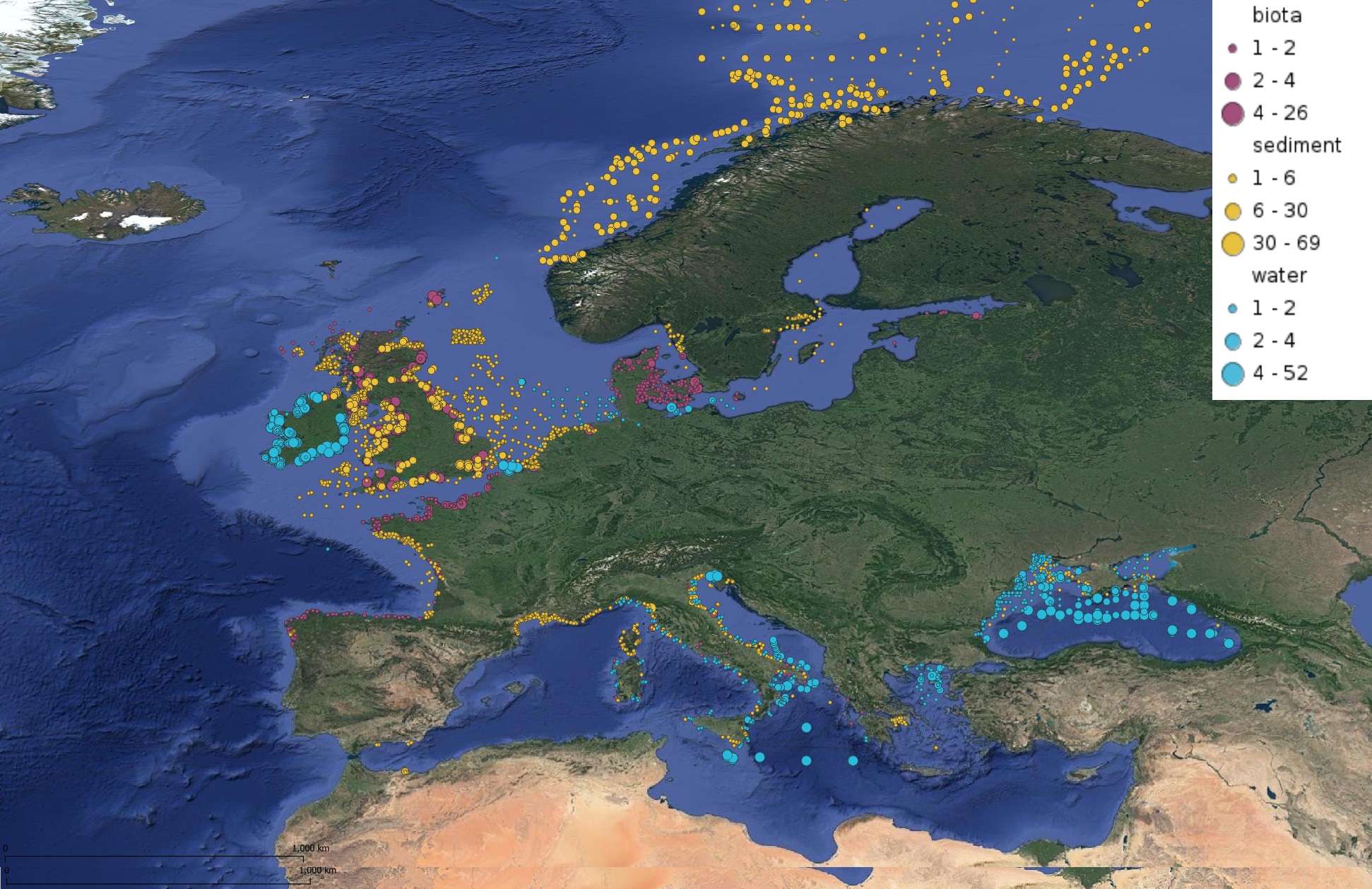
This product displays for Benzo(a)pyrene, positions with values counts that have been measured per matrix for each year and are present in EMODnet regional contaminants aggregated datasets, v2022. The product displays positions for every available year.
-

'''DEFINITION''' The OMI_EXTREME_SST_MEDSEA_sst_mean_and_anomaly_obs indicator is based on the computation of the 99th and the 1st percentiles from in situ data (observations). It is computed for the variable sea surface temperature measured by in situ buoys at depths between 0 and 5 meters. The use of percentiles instead of annual maximum and minimum values, makes this extremes study less affected by individual data measurement errors. The percentiles are temporally averaged, and the spatial evolution is displayed, jointly with the anomaly in the target year. This study of extreme variability was first applied to sea level variable (Pérez Gómez et al 2016) and then extended to other essential variables, sea surface temperature and significant wave height (Pérez Gómez et al 2018). '''CONTEXT''' Sea surface temperature (SST) is one of the essential ocean variables affected by climate change (mean SST trends, SST spatial and interannual variability, and extreme events). In Europe, several studies show warming trends in mean SST for the last years (von Schuckmann et al., 2016; IPCC, 2021, 2022). An exception seems to be the North Atlantic, where, in contrast, anomalous cold conditions have been observed since 2014 (Mulet et al., 2018; Dubois et al. 2018; IPCC 2021, 2022). Extremes may have a stronger direct influence in population dynamics and biodiversity. According to Alexander et al. 2018 the observed warming trend will continue during the 21st Century and this can result in exceptionally large warm extremes. Monitoring the evolution of sea surface temperature extremes is, therefore, crucial.The Mediterranean Sea has showed a constant increase of the SST in the last three decades across the whole basin with more frequent and severe heat waves (Juza et al., 2022). Deep analyses of the variations have displayed a non-uniform rate in space, being the warming trend more evident in the eastern Mediterranean Sea with respect to the western side. This variation rate is also changing in time over the three decades with differences between the seasons (e.g. Pastor et al. 2018; Pisano et al. 2020), being higher in Spring and Summer, which would affect the extreme values. '''COPERNICUS MARINE SERVICE KEY FINDINGS''' The mean 99th percentiles showed in the area present values from 25ºC in Ionian Sea and 26º in the Alboran sea and Gulf of Lion to 27ºC in the East of Iberian Peninsula. The standard deviation ranges from 0.6ºC to 1.2ºC in the Western Mediterranean and is around 2.2ºC in the Ionian Sea. Results for this year show a slight negative anomaly in the Ionian Sea (-1ºC) inside the standard deviation and a clear positive anomaly in the Western Mediterranean Sea reaching +2.2ºC, almost two times the standard deviation in the area. '''DOI (product):''' https://doi.org/10.48670/moi-00267
-
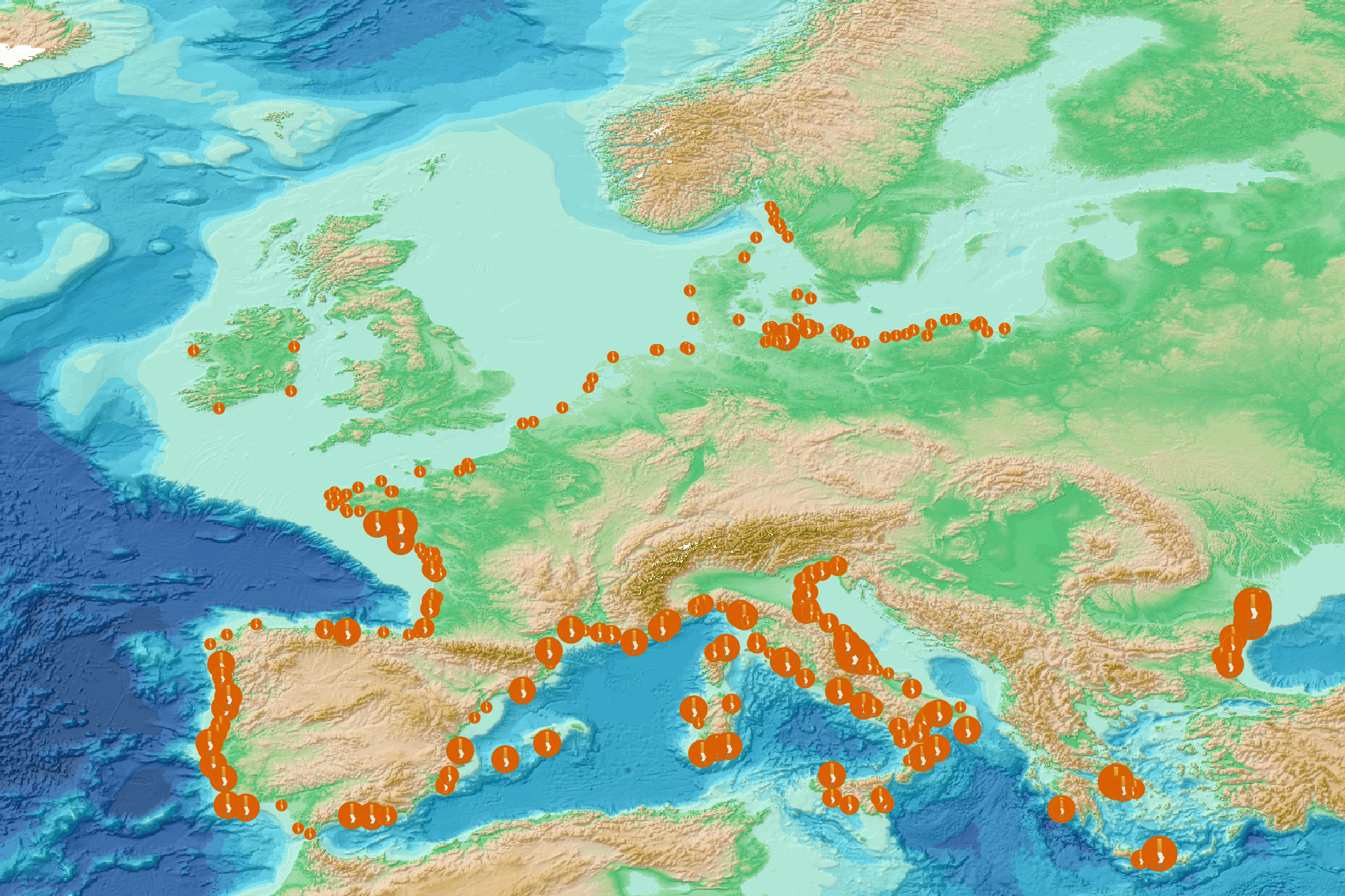
This visualization product displays the cigarette related items abundance of marine macro-litter (> 2.5cm) per beach per year from Marine Strategy Framework Directive (MSFD) monitoring surveys without UNEP-MARLIN data. EMODnet Chemistry included the collection of marine litter in its 3rd phase. Since the beginning of 2018, data of beach litter have been gathered and processed in the EMODnet Chemistry Marine Litter Database (MLDB). The harmonization of all the data has been the most challenging task considering the heterogeneity of the data sources, sampling protocols and reference lists used on a European scale. Preliminary processing were necessary to harmonize all the data: - Exclusion of OSPAR 1000 protocol: in order to follow the approach of OSPAR that it is not including these data anymore in the monitoring; - Selection of MSFD surveys only (exclusion of other monitoring, cleaning and research operations); - Exclusion of beaches without coordinates; - Selection of cigarette related items only. The list of selected items is attached to this metadata. This list was created using EU Marine Beach Litter Baselines and EU Threshold Value for Macro Litter on Coastlines from JRC (these two documents are attached to this metadata); - Exclusion of surveys referring to the UNEP-MARLIN list: the UNEP-MARLIN protocol differs from the other types of monitoring in that cigarette butts are surveyed in a 10m square. To avoid comparing abundances from very different protocols, the choice has been made to distinguish in two maps the cigarette related items results associated with the UNEP-MARLIN list from the others; - Normalization of survey lengths to 100m & 1 survey / year: in some case, the survey length was not exactly 100m, so in order to be able to compare the abundance of litter from different beaches a normalization is applied using this formula: Number of cigarette related items of the survey (normalized by 100 m) = Number of cigarette related items of the survey x (100 / survey length) Then, this normalized number of cigarette related items is summed to obtain the total normalized number of cigarette related items for each survey. Finally, the median abundance of cigarette related items for each beach and year is calculated from these normalized abundances of cigarette related items per survey. Sometimes the survey length was null or equal to 0. Assuming that the MSFD protocol has been applied, the length has been set at 100m in these cases. Percentiles 50, 75, 95 & 99 have been calculated taking into account cigarette related items from MSFD monitoring data (excluding UNEP-MARLIN protocol) for all years. More information is available in the attached documents. Warning: the absence of data on the map doesn't necessarily mean that they don't exist, but that no information has been entered in the Marine Litter Database for this area.
-
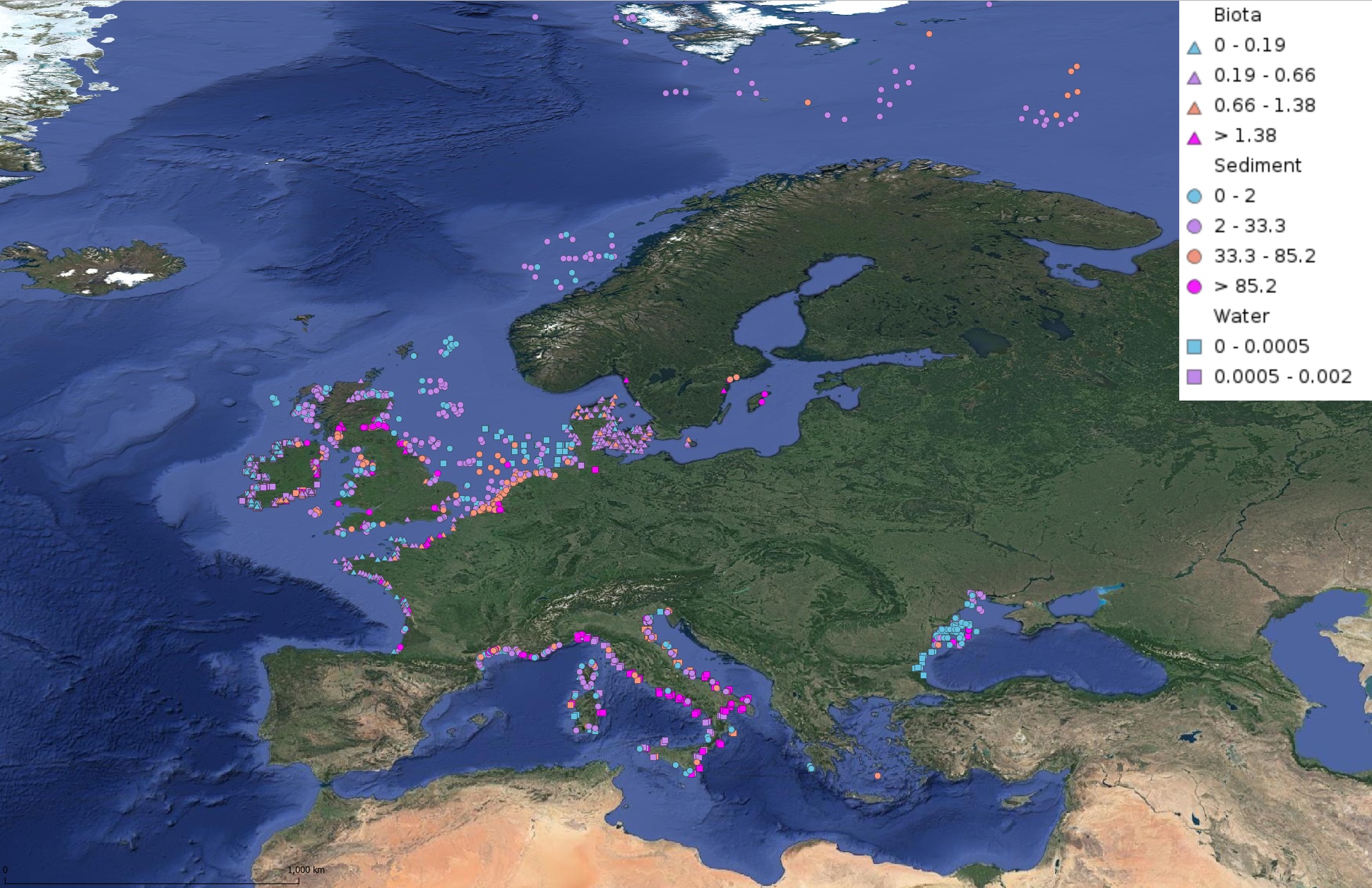
This product displays for Benzo(a)pyrene, median values of the last 6 available years that have been measured per matrix and are present in EMODnet regional contaminants aggregated datasets, v2022. The median values ranges are derived from the following percentiles: 0-25%, 25-75%, 75-90%, >90%. Only "good data" are used, namely data with Quality Flag=1, 2, 6, Q (SeaDataNet Quality Flag schema). For water, only surface values are used (0-15 m), for sediment and biota data at all depths are used.
-
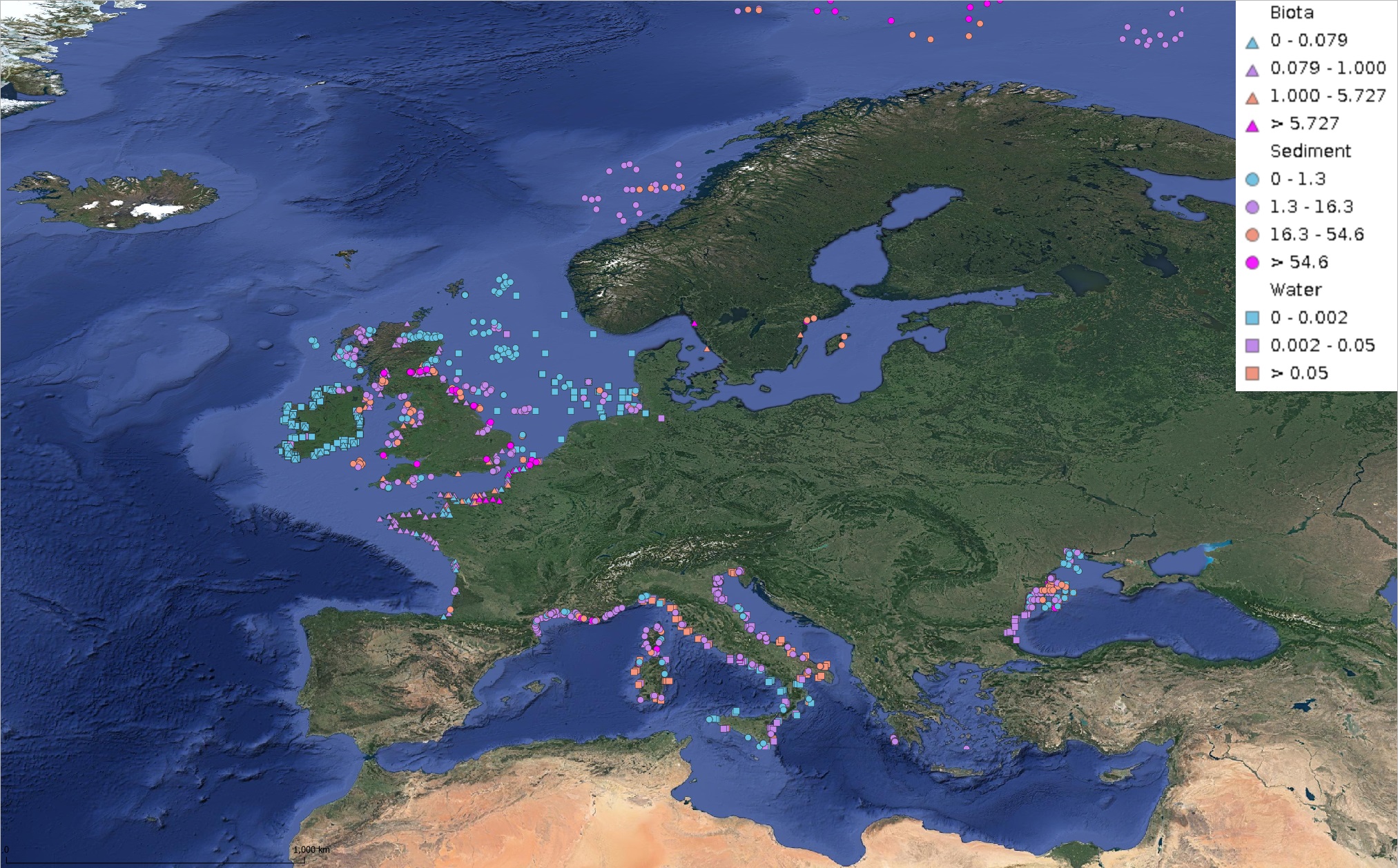
This product displays for Naphthalene, median values of the last 6 available years that have been measured per matrix and are present in EMODnet regional contaminants aggregated datasets, v2022. The median values ranges are derived from the following percentiles: 0-25%, 25-75%, 75-90%, >90%. Only "good data" are used, namely data with Quality Flag=1, 2, 6, Q (SeaDataNet Quality Flag schema). For water, only surface values are used (0-15 m), for sediment and biota data at all depths are used.