 Catalogue PIGMA
Catalogue PIGMA
NC, NETCDF
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
-

This dataset contains the dynamical outputs of a global ocean simulation coupling dynamics and biogeochemistry at ¼° over the year 2019. The simulation has been performed using the coupled circulation/ecosystem model NEMO/PISCES (https://www.nemo-ocean.eu/), which is here enhanced to perform an ensemble simulation with explicit simulation of modeling uncertainties in the physics and in the biogeochemistry. This dataset is one of the 40 members of the ensemble simulation. This study was part of the Horizon Europe project SEAMLESS (https://seamlessproject.org/Home.html), with the general objective of improving the analysis and forecast of ecosystem indicators. See Popov et al. (https://os.copernicus.org/articles/20/155/2024/) for more details on the study.
-
Ensemble simulations of the ecosystem model Apecosm (https://apecosm.org) forced by the IPSL-CM6-LR climate model with the climate change scenario SSP1-2.6. The output files contain yearly mean biomass density for 3 communities (epipelagic, mesopelagic migratory and mesopelagic redidents) and 100 size classes (ranging from 0.12cm to 1.96m) The model grid file is also provided. Units are in J/m2 and can be converted in kg/m2 by dividing by 4e6. These outputs are associated with the "Assessing the time of emergence of marine ecosystems from global to local scales using IPSL-CM6A-LR/APECOSM climate-to-fish ensemble simulations" paper from the Earth's Future "Past and Future of Marine Ecosystems" Special Collection.
-
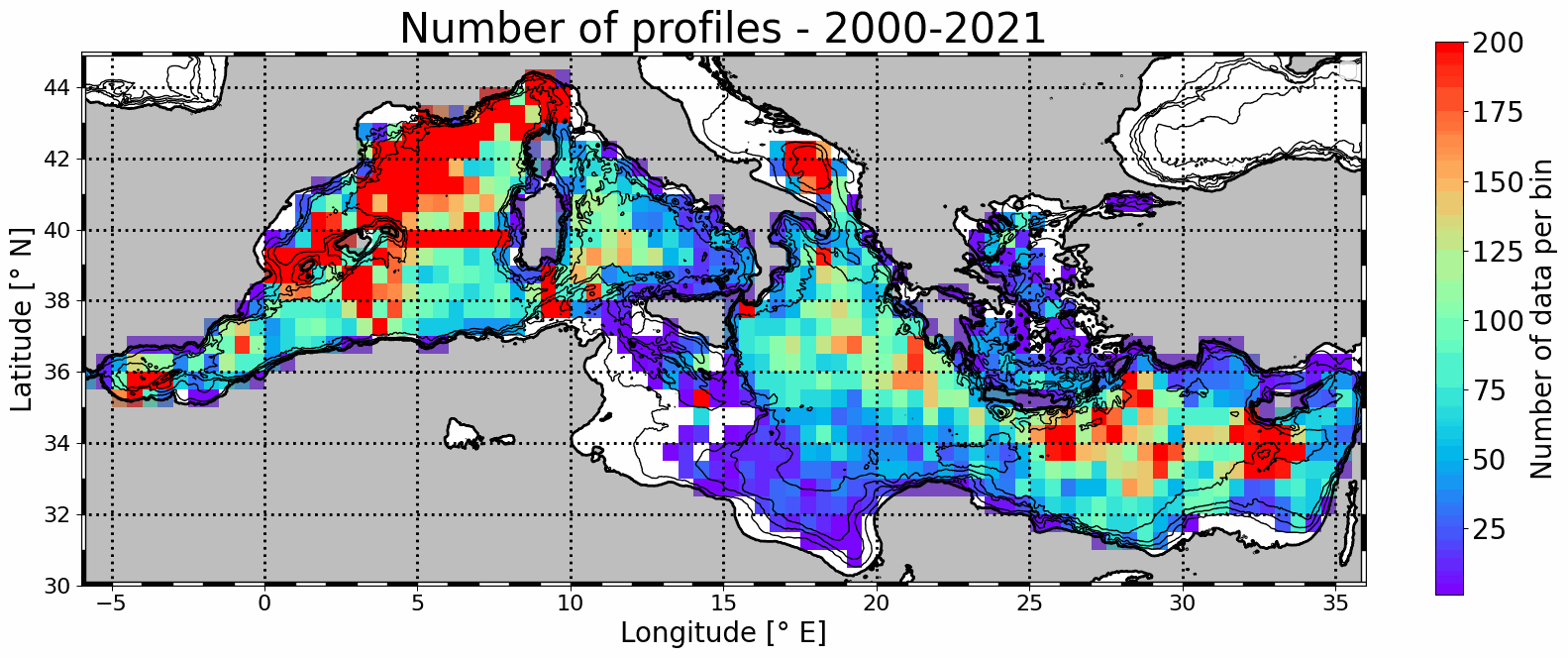
Mesoscale eddy detection from 2000 to 2021 are computed using the AMEDA algorithm applied on AVISO L4 absolute dynamic topography at 1/8th degree. Eddy numbers correspond to tracks referenced in the DYNED atlas (https://doi.org/10.14768/2019130201.2). Detection is based on AVISO delyed-time product from 2000 to 2019 and on day+6 near-real-time altimetry from 2020 to 2021. Colocalisation is then made with available in situ profiles from Coriolis Ocean Dataset for Reanalysis (CORA) delayed-time data (113486 profiles) and Copernicus near-real-time profiles (43567).
-
This In Situ delayed mode product integrates the best available version of in situ oxygen, chlorophyll / fluorescence and nutrients data. The latest version of Copernicus delayed-mode BGC (bio-geo-chemical) product is also distributed from Copernicus Marine catalogue.
-
This dataset provides a World Ocean Atlas of Argo inferred statistics. The primary data are exclusively Argo profiles. The statistics are done using the whole time range covered by the Argo data, starting in July 1997. The atlas is provided with a 0.25° resolution in the horizontal and 63 depths from 0 m to 2,000 m in the vertical. The statistics include means of Conservative Temperature (CT), Absolute Salinity, compensated density, compressiblity factor and vertical isopycnal displacement (VID); standard deviations of CT, VID and the squared Brunt Vaisala frequency; skewness and kurtosis of VID; and Eddy Available Potential Energy (EAPE). The compensated density is the product of the in-situ density times the compressibility factor. It generalizes the virtual density used in Roullet et al. (2014). The compressibility factor is defined so as to remove the dependency with pressure of the in-situ density. The compensated density is used in the computation of the VID and the EAPE.
-
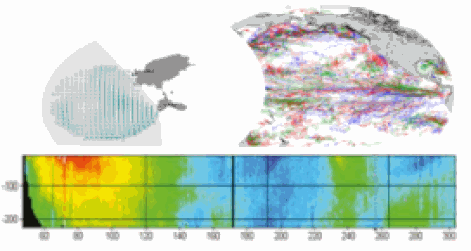
This delayed mode product designed for reanalysis purposes integrates the best available version of in situ data for ocean surface currents and current vertical profiles. It concerns three delayed time datasets dedicated to near-surface currents measurements coming from three platforms (Lagrangian surface drifters, High Frequency radars and Argo floats) and velocity profiles within the water column coming from the Acoustic Doppler Current Profiler (ADCP, vessel mounted only). The latest version of Copernicus surface and sub-surface water velocity product is also distributed from Copernicus Marine catalogue.
-
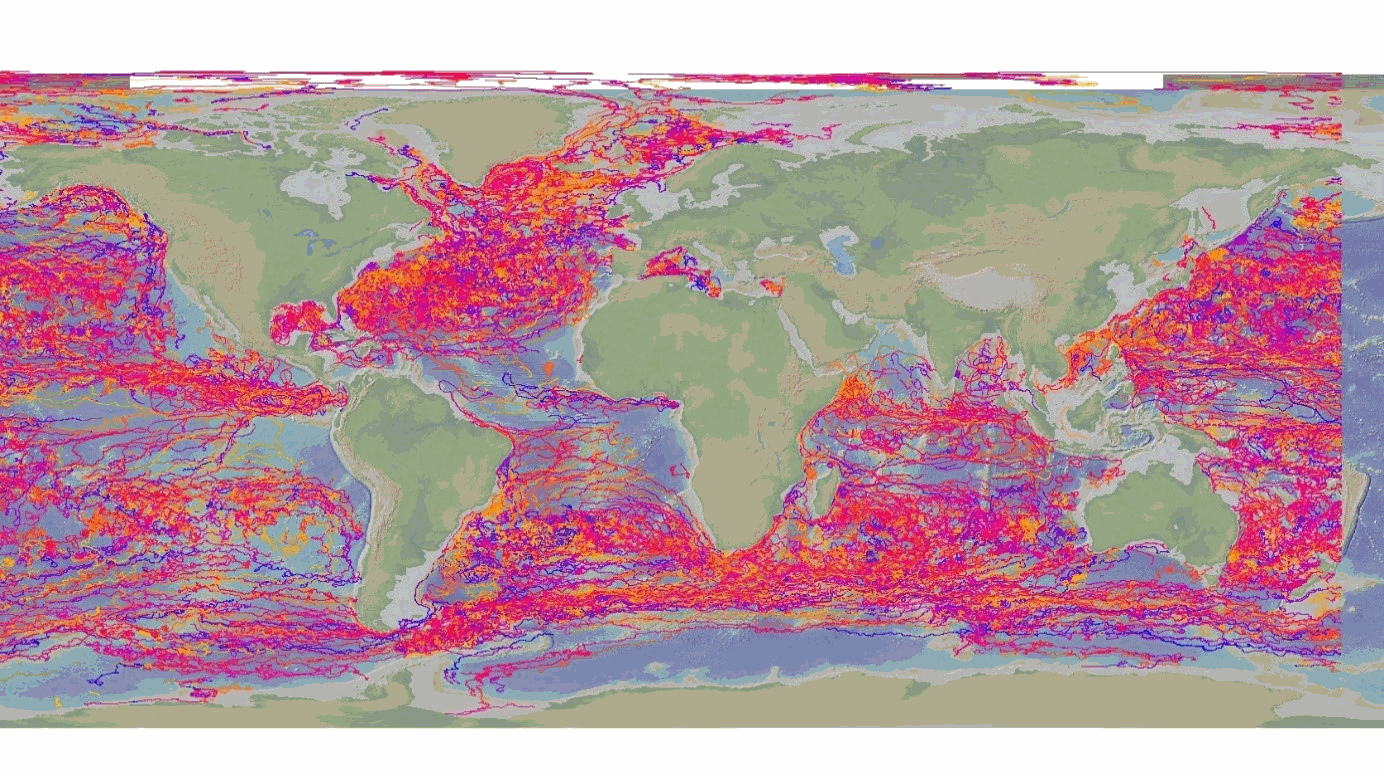
The DBCP – Data Buoy Cooperation Panel - is an international program coordinating the use of autonomous data buoys to observe atmospheric and oceanographic conditions, over ocean areas where few other measurements are taken. DBCP coordinates the global array of 1 600 active drifting buoys (August 2020) and historical observation from 14 000 drifting buoys. Data and metadata collected by drifting buoys are publically available in near real-time via the Global Data Assembly Centers (GDACs) in Coriolis-Ifremer (France) and MEDS (Canada) after an automated quality control (QC). In long term, scientifically quality controlled delayed mode data will be distributed on the GDACs. Disclaimer: the DB-GDAC is under construction. It is currently (January 2020) aggregating data from the Coriolis DAC (E-Surfmar, Canada). Additional DACs are considered. An interim provision from GTS real-time data to GDAC may be provided from Coriolis DAC.
-
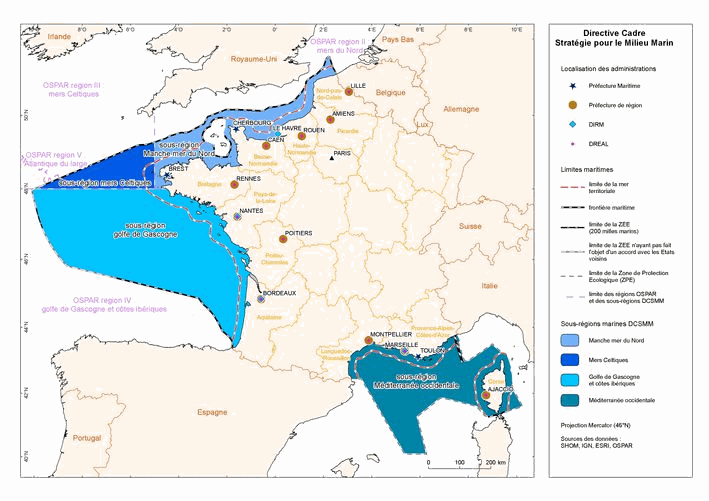
This dataset is an aggregation of all availale in situ data from Coriolis and Copernicus in situ data centres, observed in the French DCSMM area. It contains 5167 NetCDF CF files from 1903 to 2017. Each file contains the observations of a specific platform (e.g. vessel, mooring site, sea level station). Observed parameters are temperature, salinity, pressure, oxygen, nitrate, chlorophyll (and other bio-geo-chemicals), current, wave, sea level, river flow.
-

This dataset provides a global Look-Up Table (LUT) of physiological ratios for the real-time adjustment of chlorophyll-a fluorescence measured by biogeochemical Argo (BGC-Argo) profiling floats. The physiological ratios aim to account for the global variability in the relationship between fluorescence and chlorophyll-a concentration, as influenced by phytoplankton physiology. The LUT was developed using two different gap-filled observational Argo-based products (SOCA machine learning-based methodology ; Sauzède et al., 2016; Sauzède et al., 2024). The first product provides gap-filled chlorophyll-a data derived from fluorescence corrected for dark signal and non-photochemical quenching (NPQ) following Schmechtig et al. (2023), while the second product provides chlorophyll-a concentrations derived from light attenuation. The latter is based on the downward irradiance at 490 nm (ED490) derived from the SOCA-light method (Renosh et al., 2023). From this, the diffuse attenuation coefficient (KD490) is computed, which is subsequently used to estimate the chlorophyll-a concentration through the bio-optical relationships described by Morel et al. (2007). These two products, based on fluorescence and radiometry, enable the derivation of spatially varying correction factors, or physiological ratios. These ratios provide a validated grounded framework for adjusting real-time fluorescence observations from OneArgo floats into chlorophyll-a concentrations. The LUT is distributed in NetCDF format and is provided on a regular 1°×1° latitude–longitude grid covering the global ocean. Each grid cell contains the temporal mean, averaged over the water column (from the surface to 1.5 times the euphotic depth), of the physiological ratio. The file also includes metadata describing variable definitions, units, and other relevant information. Variables included: - physiological_ratio — fluorescence-to-radiometry-based chlorophyll correction factor (dimensionless) - physiological_ratio_sd — temporal standard deviation (over the twelve months) of the fluorescence-to-radiometry-based chlorophyll correction factor (dimensionless) - lat, lon — spatial coordinates (degrees north/east) - Global attributes — dataset description, reference citation, and contact information
-
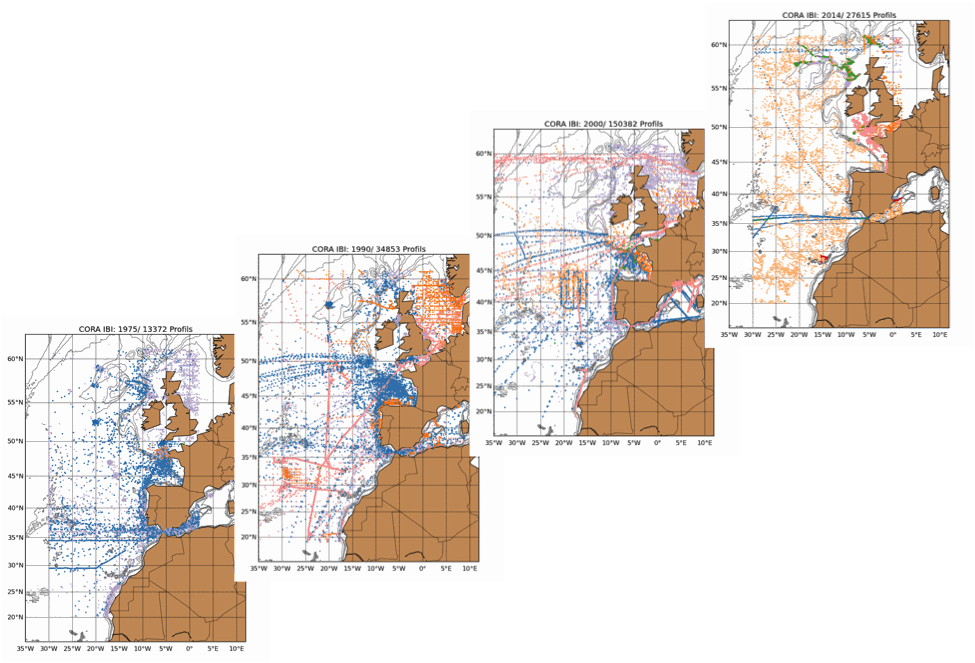
The Coriolis Ocean Dataset for Reanalysis for the Ireland-Biscay-Iberia region (hereafter CORA-IBI) product is a regional dataset of in situ temperature and salinity measurements. The latest version of the product covers the period 1950-2014. The CORA-IBI observations comes from many different sources collected by Coriolis data centre in collaboration with the In Situ Thematic Centre of the Copernicus Marine Service (CMEMS INSTAC). The observations integrated in the CORA-IBI product have been acquired both by autonomous platforms (Argo profilers, fixed moorings, gliders, drifters, sea mammals, fishery observing system from the RECOPESCA program), research or opportunity vessels ( CTDs, XBTs, ferrybox). This CORA-IBI product has been controlled using an objective analysis (statistical tests) method and a visual quality control (QC). This QC procedure has been developed with the main objective to improve the quality of the dataset to the level required by the climate application and the physical ocean re-analysis activities. It provides T and S individual profiles on their original level with QC flags. The reference level of measurements is immersion (in meters) or pressure (in decibars). It is a subset on the IBI (Iberia-Bay-of-Biscay Ireland) of the CMEMS product referenced hereafter. The main new features of this regional product compared with previous global CORA products are the incorporation of coastal profiles from fishery observing system (RECOPESCA programme) in the Bay of Biscay and the English Channel as well as the use of an historical dataset collected by the Service hydrographique de la Marine (SHOM).