 Catalogue PIGMA
Catalogue PIGMA
Marine Strategy Framework Directive
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
-
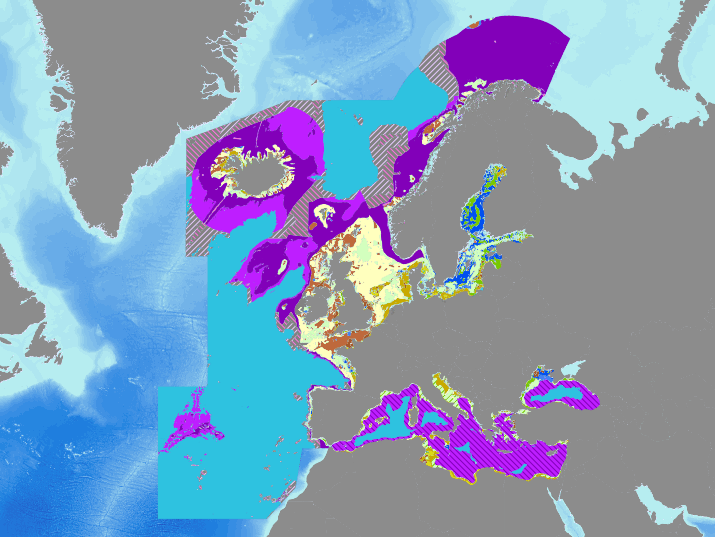
Output of the 2016 EUSeaMap broad-scale predictive model, produced by EMODnet Seabed Habitats and aggregated into the predominant habitats of the Marine Strategy Framework Directive. The extent of the mapped area includes the Mediterranean Sea, Black Sea, Baltic Sea, and areas of the North Eastern Atlantic extending from the Canary Islands in the south to Norway in the North. The map was produced using a "top-down" modelling approach using classified habitat descriptors to determine a final output habitat. Habitat descriptors differ per region but include: Biological zone Energy class Oxygen regime Salinity regime Seabed Substrate Riverine input Habitat descriptors (excepting Substrate) are calculated using underlying physical data and thresholds derived from statistical analyses or expert judgement on known conditions. The model is produced in Arc Model Builder (10.1). For more information on the modelling process please read the EMODnet Seabed Habitats The model was created using raster input layers with a cell size of 0.002dd (roughly 250 meters). The model includes the sublittoral zone only; due to the high variability of the littoral zone, a lack of detailed substrate data and the resolution of the model, it is difficult to predict littoral habitats at this scale.
-
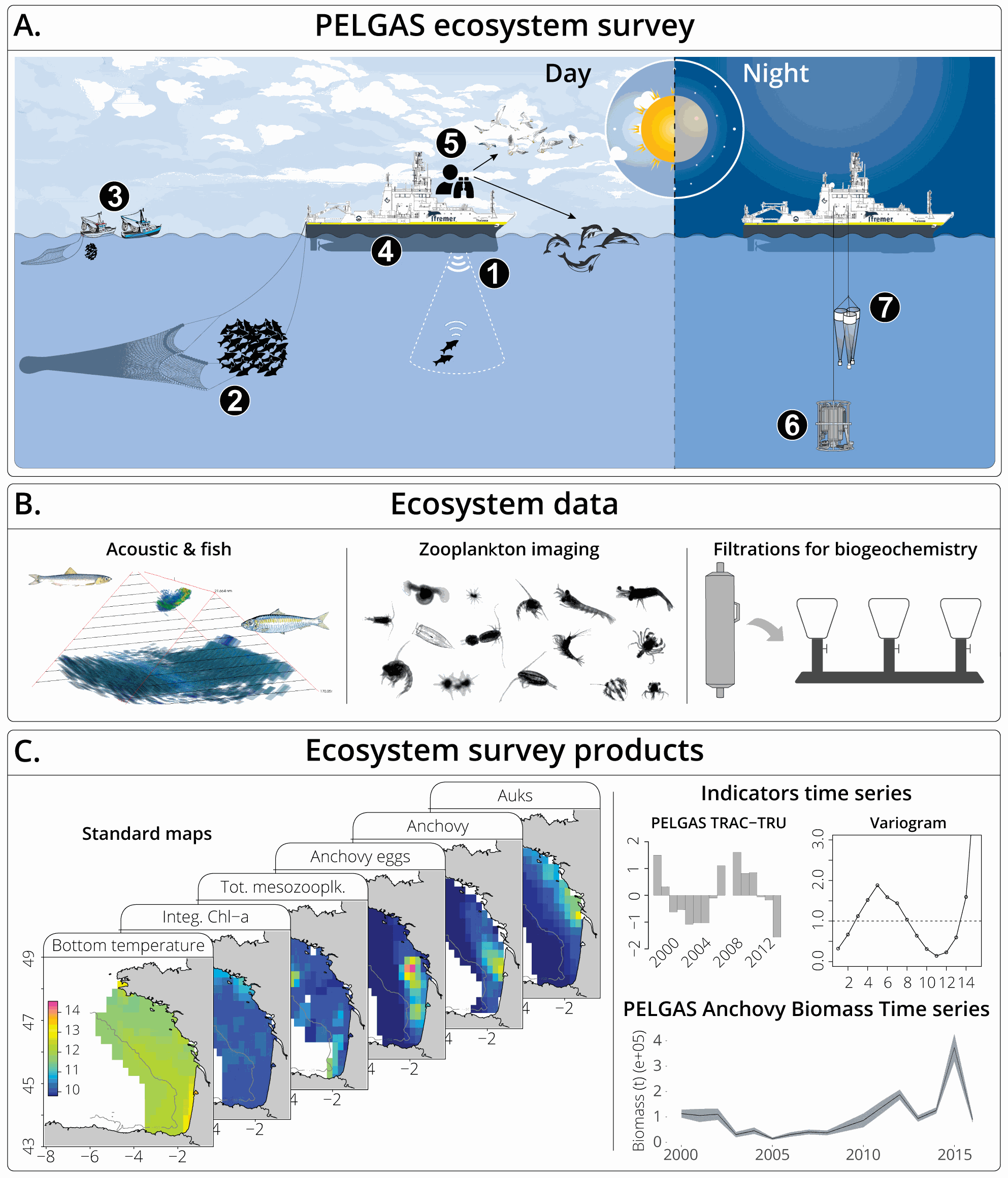
The Pélagiques Gascogne (PELGAS, Doray et al., 2000) integrated survey aims at assessing the biomass of small pelagic fish and monitoring and studying the dynamics and diversity of the Bay of Biscay pelagic ecosystem in springtime. PELGAS has been conducted within the EU Common Fisheries Policy Data Collection Framework and Ifremer’s Fisheries Information System. The PELGAS survey model has allowed for the establishment of a long-term time-series of spatially-explicit data of the Bay of Biscay pelagic ecosystem since the year 2000. Main sampled components of the targeted ecosystem are: hydrology, phytoplankton, mesozooplankton, fish and megafauna (cetacean and seabirds). This dataset presents gridded maps of standard pelagic ecosystem parameters collected in the main sampled components during the PELGAS survey. Ecosystem parameters were mapped on a 15km x 15km grid by applying a block averaging procedure (Petitgas et al., 2009, 2014). The dataset also includes the ecologically meaningful survey dates proposed by Huret et al. (2017), mapped on the same grid. Details on survey protocols and data processing methodologies can be found in Doray et al., (2014, 2017a). This dataset was used in Authier et al., 2017; Doray et al., 2017b, 2017c, 2017a; Huret et al., 2017; Petitgas et al., 2017.
-

Ifremer conducts numerous fisheries surveys dedicated to benthic and demersal populations (commercial / non-commercial fishes and invertebrates). For several years, in application of the ecosystem approach, all benthic invertebrate fauna collected in fishing gear has been systematically monitored: megabenthic invertebrates captured have been sorted, identified, counted and weighted. All these surveys are based on fixed or random stratified sampling strategy with varying intensity depending on the covered survey area. These data are stored, in historical access-based databases or for the most recent years in the centralised “Harmonie” database held in the Ifremer Fishery Information Systeme (SIH). The species nomenclature used was standardized using WoRMS database. Taxa caught at least once a year are listed for each monitoring area on the basis of already available data series. In order to facilitate the identification of individuals sampled on board vessels and to improve the training of onboard scientists, the present work aims to define the minimum level of identification for each of them. The analysis identifies taxa that appears recurrently on available historical series or gathers them on less precise taxonomic levels if this is not the case, which may indicate potential identification difficulties. The following procedure was used: all taxa expressed at the species level were first aggregated at genus level if they occurred less 90% of the years over the available time series. For MEDITS, EPIBENGOL and ORHAGO, the occurrence threshold was set to 70% and to only 50% for NOURMONT because the datasets were less than 10 years long. Then to be kept at that taxonomic level, a given genus had to be observed over 90% of the time (for example over at least 9 years if the dataset contains 10 years). Otherwise it was iteratively regrouped into a higher taxonomic level (family, order, class, division) following the same criteria (Foveau et al, 2017). For instance, for the NOURSEINE survey, this resulted into the aggregation of the 103 origin taxa into 35 taxonomic groups. The name of the final taxon after data processing represents the minimum level of identification defined by the analysis. However, these results are very theoretical. This is why they were sent to scientists who embark regularly in order to refine the level of taxonomic identification with field experience. The first dataset is composed of 8 tables relevant to the different vessel surveys. The first column of each table represents the permanent code of the taxon in the Ifremer taxonomic referential, the second the systematic number and the third the species abbreviated code. The other columns are the different taxonomic levels of the taxon. The minimum level of identification at sea defined by the data processing appears in blue. The level determined by feedback of scientist’s field experience, which is the one to use at sea, appears in green. The second dataset summaries the results detailed in the first table and indicates directly for each taxon identified to far, the minimum level of identification required for the benthic invertebrates by-catch of each fisheries surveys studied.
-
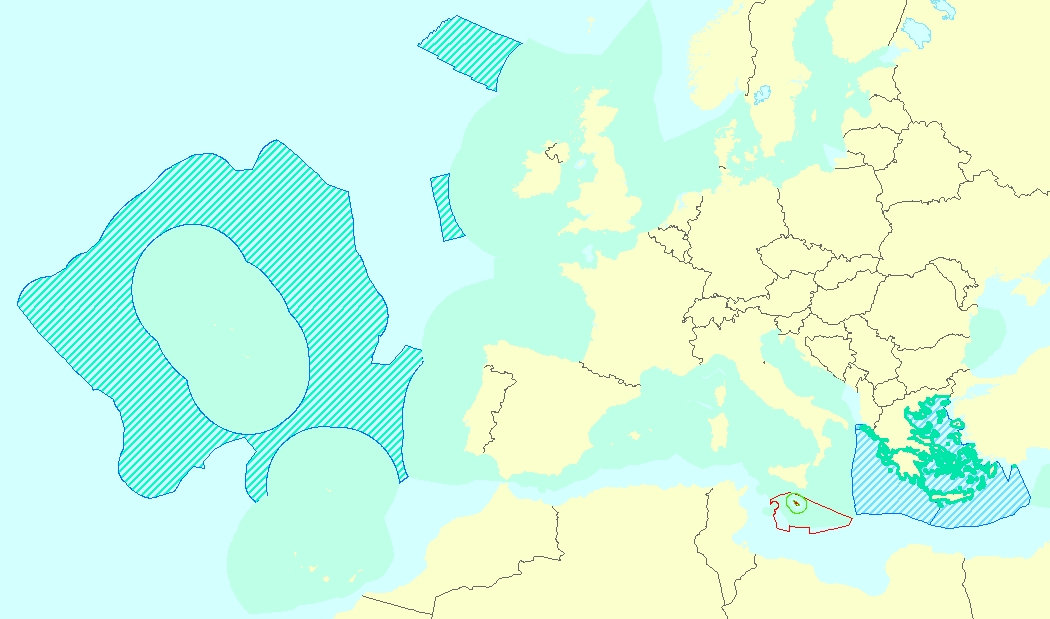
This vector data set is the first public version released of the EU marine waters used for the implementation of the Marine Strategy Framework Directive (MSFD), submitted by the Member States to the European Commission. The Marine Strategy Framework Directive (MSFD) applies to all marine waters of EU Member States, which in Article 3 are defined as follows: (a) waters, the seabed and subsoil on the seaward side of the baseline from which the extent of territorial waters is measured extending to the outmost reach of the area where a Member State has and/or exercises jurisdictional rights, in accordance with the UNCLOS, with the exception of waters adjacent to the countries and territories mentioned in Annex II to the Treaty and the French Overseas Departments and Collectivities; and (b) coastal waters as defined by Directive 2000/60/EC, their seabed and their subsoil, in so far as particular aspects of the environmental status of the marine environment are not already addressed through that Directive or other Community legislation.
-
The Marine Reporting Units (MRUs) are used within the reporting obligations of the Marine Strategy Framework Directive (MSFD) in order to link the implementation of the different articles to specific marine areas. The MRUs can be of varying sizes, according to the appropriate scale for the different reports (e.g. region, sub-region, regional or sub-regional subdivision, Member State marine waters, WFD coastal waters, etc.), as indicated in the Good Environmental Status 2017 Decision. The present data set is the first public version released of the MRUs used during the first cycle of implementation of the MSFD (2012-2018) in all the reporting exercises (2012 reporting of Articles 8, 9 and 10; 2014 reporting of Article 11; and 2016 reporting of Articles 13 & 14). The data set is distributed in SHP and in INSPIRE-compliant GML format.
-
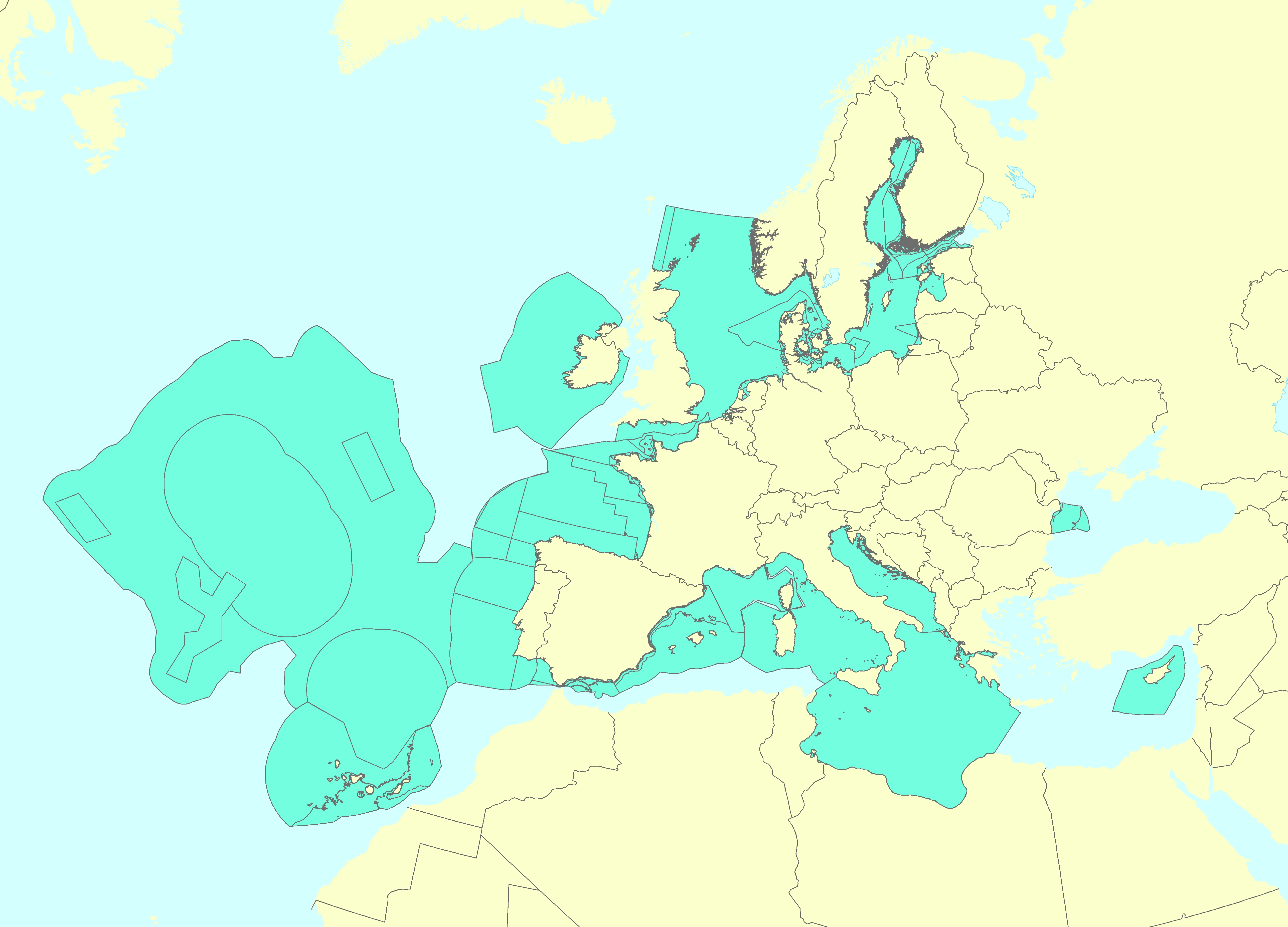
The Marine Reporting Units (MRUs) are used within the reporting obligations of the Marine Strategy Framework Directive (MSFD) in order to link the implementation of the different articles to specific marine areas. The MRUs can be of varying sizes, according to the appropriate scale for the different reports (e.g. region, sub-region, regional or sub-regional subdivision, Member State marine waters, WFD coastal waters, etc.), as indicated in the Good Environmental Status 2017 Decision. The present data set is the second public version released of the MRUs used during the MSFD 2018 reporting exercise on the update of Articles 8, 9 and 10. Only the MRUs of those countries that have gone through the reporting exercise by June 2020 have been included in this data set. Apart from the countries included already in version 1 of the dataset (SE, FI, EE, LV, PL, DE, DK, NL, BE, FR, ES, HR and RO), this version also includes seven more countries, namely MT, LT, IT, SI, CY, PT and IE. The data set is distributed in SHP and in INSPIRE-compliant GML format, made available also through an INSPIRE compliant ATOM service.