 Catalogue PIGMA
Catalogue PIGMA
oceans
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
Resolution
-

'''Short description:''' Le modèle biogéochimique ECO-MARS3D sur la façade Manche Atlantique (PREVIMER_B1-ECOMARS3D-MANGA4000) est un modèle 3D de résolution spatiale 4km qui fournit les concentrations de nutriments et de plancton toutes les heures sur 30 niveaux (fenêtre de prévision à 4 jours). '''Paramètres calculés :''' Les paramètres calculés sont les suivants : * SAL : sea_water_salinity * TEMP : sea_water_temperature * suspended_inorganic_particulate_matter : mass_concentration_of_suspended_matter_in_sea_water * nanopicoplankton_nitrogen : mole_concentration_of_nanoplankton_expressed_as_nitrogen_in_sea_water * diatom_nitrogen : mole_concentration_of_diatoms_expressed_as_nitrogen_in_sea_water * dinoflagellate_nitrogen : mole_concentration_of_dinoflagellates_expressed_as_nitrogen_in_sea_water * microzooplankton_nitrogen : mole_concentration_of_microzooplankton_expressed_as_nitrogen_in_sea_water * mesozooplankton_nitrogen : mole_concentration_of_mesozooplankton_expressed_as_nitrogen_in_sea_water * colonial_phaeocystis_nitrogen : mole_concentration_of_colonial_phaeocystis_expressed_as_nitrogen_in_sea_water * phaeocystis_mucus : concentration_of_phaeocystis_mucus_expressed_as_mass_in_sea_water * ammonium : mole_concentration_of_ammonium_in_sea_water * nitrate : mole_concentration_of_nitrate_in_sea_water * dissolved_silicate : mole_concentration_of_silicate_in_sea_water * dissolved_phosphate : mole_concentration_of_phosphate_in_sea_water * dissolved_oxygen : dissolved_oxygen_in_water_column * cumulative_nanoflagellate_carbon_production : cumulative_nanoflagellate_production_expressed_as_carbon_in_sea_water * cumulative_diatom_carbon_production : cumulative_diatom_production_expressed_as_carbon_in_sea_water * cumulative_dinoflagellate_carbon_production : cumulative_dinoflagellate_production_expressed_as_carbon_in_sea_water * cumulative_phaeocystis_carbon_production : cumulative_phaeocystis_production_expressed_as_carbon_in_sea_water * organic_nitrogen_benth : mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_benthos Les paramètres diagnostiques calculés sont les suivants : * XE : sea_surface_height_above_geoid * maximum_de_diat : maximum_diatom_mass_concentration_in_sea_water * maximum_de_dino : maximum_dinoflagellate_mass_concentration_in_sea_water * maximum_de_nano : maximum_nanoflagellate_mass_concentration_in_sea_water * grad_vert_salinite : maximum_vertical_gradient_of_sea_water_salinity * grad_vert_temp : maximum_vertical_gradient_of_sea_water_temperature * extinction_lumineuse : light_extinction_in_sea_water * prod_diat : cumulated_production_of_diatoms_in_sea_water_column_expressed_in_carbon * prod_dino : cumulated_production_of_dinoflagellates_in_sea_water_column_expressed_in_carbon * prod_nano : cumulated_production_of_nanoflagellates_in_sea_water_column_expressed_in_carbon * chlorophylle_a : chlorophyll_mass_concentration_in_sea_water * prod_cumul_chloro : cumulated_total_production_in_sea_water_column_expressed_in_carbon * maximum_de_phaeocystis : maximum_phaeocystis_mass_concentration_in_sea_water * prod_phaeocystis : cumulated_production_of_phaeocystis_in_sea_water_column_expressed_in_carbon * oxygen_saturation : oxygen_saturation * ammoniumGIRON_tracer_sign: mole_concentration_of_ammonium_in_sea_waterGIRON_tracer_sign * ammoniumGIRON_tracer_age: mole_concentration_of_ammonium_in_sea_waterGIRON_tracer_age * nitrateGIRON_tracer_sign: mole_concentration_of_nitrate_in_sea_waterGIRON_tracer_sign * nitrateGIRON_tracer_age: mole_concentration_of_nitrate_in_sea_waterGIRON_tracer_age * nanopicoplankton_nitrogenGIRON_tracer_sign: mole_concentration_of_nanoplankton_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * nanopicoplankton_nitrogenGIRON_tracer_age: mole_concentration_of_nanoplankton_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * diatom_nitrogenGIRON_tracer_sign: mole_concentration_of_diatoms_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * diatom_nitrogenGIRON_tracer_age: mole_concentration_of_diatoms_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * dinoflagellate_nitrogenGIRON_tracer_sign: mole_concentration_of_dinoflagellates_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * dinoflagellate_nitrogenGIRON_tracer_age: mole_concentration_of_dinoflagellates_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * microzooplankton_nitrogenGIRON_tracer_sign: mole_concentration_of_microzooplankton_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * microzooplankton_nitrogenGIRON_tracer_age: mole_concentration_of_microzooplankton_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * mesozooplankton_nitrogenGIRON_tracer_sign: mole_concentration_of_mesozooplankton_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * mesozooplankton_nitrogenGIRON_tracer_age: mole_concentration_of_mesozooplankton_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * detrital_nitrogenGIRON_tracer_sign: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * detrital_nitrogenGIRON_tracer_age: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * colonial_phaeocystis_nitrogenGIRON_tracer_sign: mole_concentration_of_colonial_phaeocystis_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * colonial_phaeocystis_nitrogenGIRON_tracer_age: mole_concentration_of_colonial_phaeocystis_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * phaeocystis_cells_nitrogenGIRON_tracer_sign: mole_concentration_of_phaeocystis_cells_expressed_as_nitrogen_in_sea_waterGIRON_tracer_sign * phaeocystis_cells_nitrogenGIRON_tracer_age: mole_concentration_of_phaeocystis_cells_expressed_as_nitrogen_in_sea_waterGIRON_tracer_age * organic_nitrogen_benthGIRON_tracer_sign: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_benthosGIRON_tracer_sign * organic_nitrogen_benthGIRON_tracer_age: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_benthosGIRON_tracer_age * phytoplankton_sign_N_GIRON: nitrogen_fraction_in_phytoplankton_from_source_GIRON * phytoplankton_age_N_GIRON: age_of_nitrogen_fraction_in_phytoplankton_from_source_GIRON * ammoniumLOIRE_tracer_sign: mole_concentration_of_ammonium_in_sea_waterLOIRE_tracer_sign * ammoniumLOIRE_tracer_age: mole_concentration_of_ammonium_in_sea_waterLOIRE_tracer_age * nitrateLOIRE_tracer_sign: mole_concentration_of_nitrate_in_sea_waterLOIRE_tracer_sign * nitrateLOIRE_tracer_age: mole_concentration_of_nitrate_in_sea_waterLOIRE_tracer_age * nanopicoplankton_nitrogenLOIRE_tracer_sign: mole_concentration_of_nanoplankton_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * nanopicoplankton_nitrogenLOIRE_tracer_age: mole_concentration_of_nanoplankton_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * diatom_nitrogenLOIRE_tracer_sign: mole_concentration_of_diatoms_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * diatom_nitrogenLOIRE_tracer_age: mole_concentration_of_diatoms_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * dinoflagellate_nitrogenLOIRE_tracer_sign: mole_concentration_of_dinoflagellates_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * dinoflagellate_nitrogenLOIRE_tracer_age: mole_concentration_of_dinoflagellates_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * microzooplankton_nitrogenLOIRE_tracer_sign: mole_concentration_of_microzooplankton_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * microzooplankton_nitrogenLOIRE_tracer_age: mole_concentration_of_microzooplankton_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * mesozooplankton_nitrogenLOIRE_tracer_sign: mole_concentration_of_mesozooplankton_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * mesozooplankton_nitrogenLOIRE_tracer_age: mole_concentration_of_mesozooplankton_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * detrital_nitrogenLOIRE_tracer_sign: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * detrital_nitrogenLOIRE_tracer_age: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * colonial_phaeocystis_nitrogenLOIRE_tracer_sign: mole_concentration_of_colonial_phaeocystis_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * colonial_phaeocystis_nitrogenLOIRE_tracer_age: mole_concentration_of_colonial_phaeocystis_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * phaeocystis_cells_nitrogenLOIRE_tracer_sign: mole_concentration_of_phaeocystis_cells_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_sign * phaeocystis_cells_nitrogenLOIRE_tracer_age: mole_concentration_of_phaeocystis_cells_expressed_as_nitrogen_in_sea_waterLOIRE_tracer_age * organic_nitrogen_benthLOIRE_tracer_sign: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_benthosLOIRE_tracer_sign * organic_nitrogen_benthLOIRE_tracer_age: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_benthosLOIRE_tracer_age * phytoplankton_sign_N_LOIRE: nitrogen_fraction_in_phytoplankton_from_source_LOIRE * phytoplankton_age_N_LOIRE: age_of_nitrogen_fraction_in_phytoplankton_from_source_LOIRE * ammoniumSEINE_tracer_sign: mole_concentration_of_ammonium_in_sea_waterSEINE_tracer_sign * ammoniumSEINE_tracer_age: mole_concentration_of_ammonium_in_sea_waterSEINE_tracer_age * nitrateSEINE_tracer_sign: mole_concentration_of_nitrate_in_sea_waterSEINE_tracer_sign * nitrateSEINE_tracer_age: mole_concentration_of_nitrate_in_sea_waterSEINE_tracer_age * nanopicoplankton_nitrogenSEINE_tracer_sign: mole_concentration_of_nanoplankton_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * nanopicoplankton_nitrogenSEINE_tracer_age: mole_concentration_of_nanoplankton_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * diatom_nitrogenSEINE_tracer_sign: mole_concentration_of_diatoms_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * diatom_nitrogenSEINE_tracer_age: mole_concentration_of_diatoms_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * dinoflagellate_nitrogenSEINE_tracer_sign: mole_concentration_of_dinoflagellates_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * dinoflagellate_nitrogenSEINE_tracer_age: mole_concentration_of_dinoflagellates_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * microzooplankton_nitrogenSEINE_tracer_sign: mole_concentration_of_microzooplankton_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * microzooplankton_nitrogenSEINE_tracer_age: mole_concentration_of_microzooplankton_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * mesozooplankton_nitrogenSEINE_tracer_sign: mole_concentration_of_mesozooplankton_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * mesozooplankton_nitrogenSEINE_tracer_age: mole_concentration_of_mesozooplankton_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * detrital_nitrogenSEINE_tracer_sign: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * detrital_nitrogenSEINE_tracer_age: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * colonial_phaeocystis_nitrogenSEINE_tracer_sign: mole_concentration_of_colonial_phaeocystis_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * colonial_phaeocystis_nitrogenSEINE_tracer_age: mole_concentration_of_colonial_phaeocystis_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * phaeocystis_cells_nitrogenSEINE_tracer_sign: mole_concentration_of_phaeocystis_cells_expressed_as_nitrogen_in_sea_waterSEINE_tracer_sign * phaeocystis_cells_nitrogenSEINE_tracer_age: mole_concentration_of_phaeocystis_cells_expressed_as_nitrogen_in_sea_waterSEINE_tracer_age * organic_nitrogen_benthSEINE_tracer_sign: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_benthosSEINE_tracer_sign * organic_nitrogen_benthSEINE_tracer_age: mole_concentration_of_organic_detritus_expressed_as_nitrogen_in_benthosSEINE_tracer_age * phytoplankton_sign_N_SEINE: nitrogen_fraction_in_phytoplankton_from_source_SEINE * phytoplankton_age_N_SEINE: age_of_nitrogen_fraction_in_phytoplankton_from_source_SEINE
-

'''Short description:''' For the Baltic Sea- The DMI Sea Surface Temperature L3S aims at providing daily multi-sensor supercollated data at 0.03deg. x 0.03deg. horizontal resolution, using satellite data from infra-red radiometers. Uses SST satellite products from these sensors: NOAA AVHRRs 7, 9, 11, 14, 16, 17, 18 , Envisat ATSR1, ATSR2 and AATSR. '''DOI (product) :''' https://doi.org/10.48670/moi-00154
-
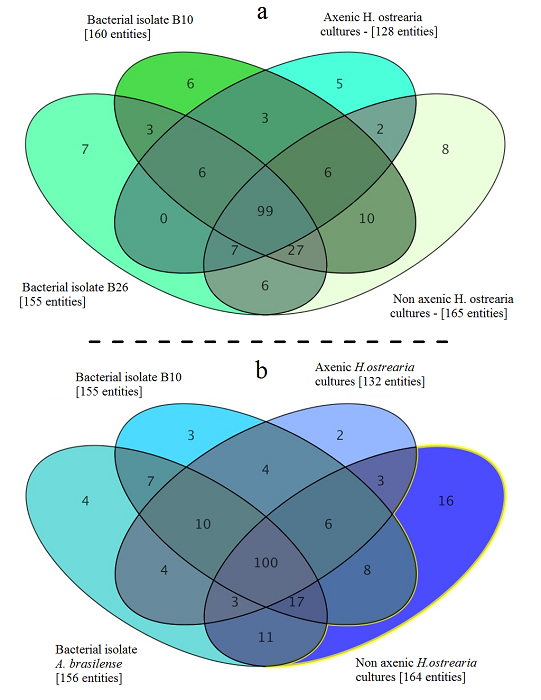
Metabolome of of the marine diatom Haslea ostrearia. Bacteria were isolated from Haslea ostrearia isolates cultivated in ES 1/3 medium in laboratory conditions over a 3-month period. These microalgal isolates were recovered from four sites on the French Atlantic coast: Bouin , La Barre-de-Monts (46.90 N; 2.11°W), Isle de Ré (46.22 N; 1.45°W), and La Tremblade (45.80 N; 1.15°W) . Data processing and statistical analysis of the metabolic profiles were performed on an LC/MS Metabolomics Discovery Workflow using Mass Profiler Professional Software and an Agilent 1290 Infinity II LC system coupled to an Agilent 6540 UHD Accurate-Mass QTOF hybrid mass spectrometer (Agilent Technologies, Waldbronn, Germany) equipped with a dual electrospray ionization (ESI) source. The full history (tools, parameters, input and output data files) is publicly available on http://dx.doi.org/10.12770/046e1e6a-864e-48a6-944b-d8613d67de0f
-
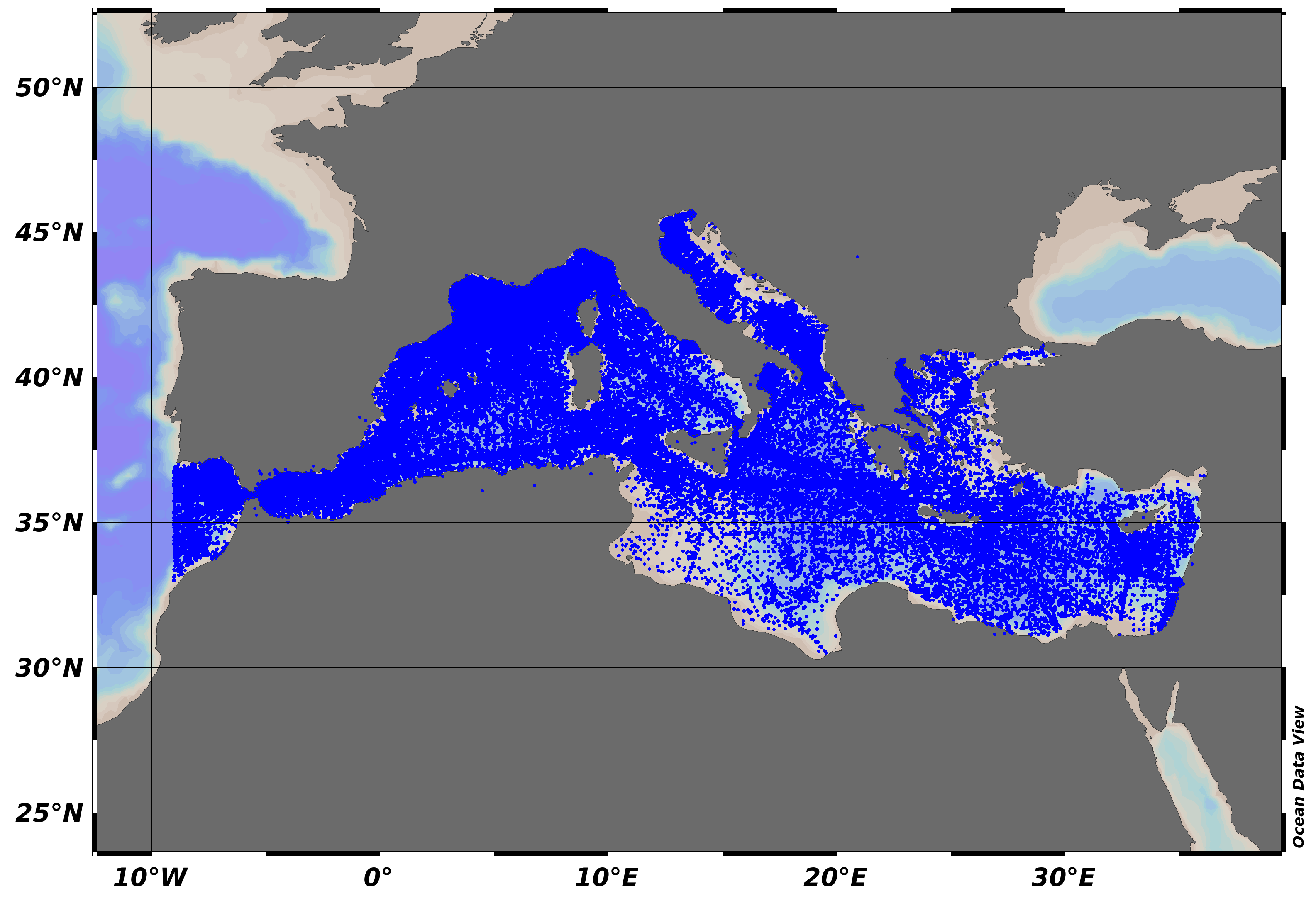
SeaDataNet Temperature and Salinity historical data collection contains all open access temperature and salinity in situ data retrieved from SeaDataNet infrastructure at the end of 2013. The data span between -9.25 and 37 degrees of longitude, thus including an Atlantic box and Marmara Sea, and cover the time period 1900-2012. Data have been quality checked using ODV software. Quality Flags of anomalous data have been revised using basic QC procedures. For data access please register at http://www.marine-id.org The dataset format is ODV binary collections. You can read, analyse and export from the ODV application provided by Alfred Wegener institute at http://odv.awi.de/
-

'''Short description:''' DTU Space produces polar covering Near Real Time gridded ice displacement fields obtained by MCC processing of Sentinel-1 SAR, Envisat ASAR WSM swath data or RADARSAT ScanSAR Wide mode data . The nominal temporal span between processed swaths is 24hours, the nominal product grid resolution is a 10km. '''DOI (product) :''' https://doi.org/10.48670/moi-00135
-

'''This product has been archived''' '''DEFINITION''' Estimates of Ocean Heat Content (OHC) are obtained from integrated differences of the measured temperature and a climatology along a vertical profile in the ocean (von Schuckmann et al., 2018). The regional OHC values are then averaged from 60°S-60°N aiming i) to obtain the mean OHC as expressed in Joules per meter square (J/m2) to monitor the large-scale variability and change. ii) to monitor the amount of energy in the form of heat stored in the ocean (i.e. the change of OHC in time), expressed in Watt per square meter (W/m2). Ocean heat content is one of the six Global Climate Indicators recommended by the World Meterological Organisation for Sustainable Development Goal 13 implementation (WMO, 2017). '''CONTEXT''' Knowing how much and where heat energy is stored and released in the ocean is essential for understanding the contemporary Earth system state, variability and change, as the ocean shapes our perspectives for the future (von Schuckmann et al., 2020). Variations in OHC can induce changes in ocean stratification, currents, sea ice and ice shelfs (IPCC, 2019; 2021); they set time scales and dominate Earth system adjustments to climate variability and change (Hansen et al., 2011); they are a key player in ocean-atmosphere interactions and sea level change (WCRP, 2018) and they can impact marine ecosystems and human livelihoods (IPCC, 2019). '''CMEMS KEY FINDINGS''' Since the year 2005, the upper (0-700m) near-global (60°S-60°N) ocean warms at a rate of 0.6 ± 0.1 W/m2. Note: The key findings will be updated annually in November, in line with OMI evolutions. '''DOI (product):''' https://doi.org/10.48670/moi-00234
-

Moving 6-year analysis of Water body silicate in the Mediterranean Sea for each season: - winter: January-March, - spring: April-June, - summer: July-September, - autumn: October-December. Every year of the time dimension corresponds to the 6-year centered average of the season. 6-years periods span from 1970-1975 until 2018-2023. Description of DIVA analysis: The computation was done with the DIVAnd (Data-Interpolating Variational Analysis in n dimensions), version 2.7.12, using GEBCO 30sec topography for the spatial connectivity of water masses. The horizontal resolution of the produced DIVAnd maps grids is dx=dy=0.125 degrees (around 13.5km and 10.9km accordingly). The vertical resolution is 25 depth levels: [0.,5.,10.,20.,30.,50.,75.,100.,125.,150.,200.,250.,300.,400.,500.,600.,700.,800.,900.,1000.,1100.,1200.,1300.,1400.,1500.]. The horizontal correlation length is 200km. The vertical correlation length (in meters) was set twices the vertical resolution: [10.,10.,20.,20.,40.,50.,50.,50.,50.,100.,100.,100.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.,200.]. Duplicates check was performed using the following criteria for space and time: dlon=0.001deg., dlat=0.001deg., ddepth=1m, dtime=1hour, dvalue=0.1. The error variance (epsilon2) was set equal to 1 for profiles and 10 for time series to reduce the influence of close data near the coasts. An anamorphosis transformation was applied to the data (function DIVAnd.Anam.loglin) to avoid unrealistic negative values: threshold value=200. A background analysis field was used for all years (1970-2023) with correlation length equal to 600km and error variance (epsilon2) equal to 20. Quality control of the observations was applied using the interpolated field (QCMETHOD=3). Residuals (differences between the observations and the analysis (interpolated linearly to the location of the observations) were calculated. Observations with residuals outside the minimum and maximum values of the 99% quantile were discarded from the analysis. Originators of Italian data sets-List of contributors: - Brunetti Fabio (OGS) - Cardin Vanessa, Bensi Manuel doi:10.6092/36728450-4296-4e6a-967d-d5b6da55f306 - Cardin Vanessa, Bensi Manuel, Ursella Laura, Siena Giuseppe doi:10.6092/f8e6d18e-f877-4aa5-a983-a03b06ccb987 - Cataletto Bruno (OGS) - Cinzia Comici Cinzia (OGS) - Civitarese Giuseppe (OGS) - DeVittor Cinzia (OGS) - Giani Michele (OGS) - Kovacevic Vedrana (OGS) - Mosetti Renzo (OGS) - Solidoro C.,Beran A.,Cataletto B.,Celussi M.,Cibic T.,Comici C.,Del Negro P.,De Vittor C.,Minocci M.,Monti M.,Fabbro C.,Falconi C.,Franzo A.,Libralato S.,Lipizer M.,Negussanti J.S.,Russel H.,Valli G., doi:10.6092/e5518899-b914-43b0-8139-023718aa63f5 - Celio Massimo (ARPA FVG) - Malaguti Antonella (ENEA) - Fonda Umani Serena (UNITS) - Bignami Francesco (ISAC/CNR) - Boldrini Alfredo (ISMAR/CNR) - Marini Mauro (ISMAR/CNR) - Miserocchi Stefano (ISMAR/CNR) - Zaccone Renata (IAMC/CNR) - Lavezza, R., Dubroca, L. F. C., Ludicone, D., Kress, N., Herut, B., Civitarese, G., Cruzado, A., Lefèvre, D.,Souvermezoglou, E., Yilmaz, A., Tugrul, S., and Ribera d'Alcala, M.: Compilation of quality controlled nutrient profiles from the Mediterranean Sea, doi:10.1594/PANGAEA.771907, 2011.
-

'''This product has been archived''' "''DEFINITION''' Marine primary production corresponds to the amount of inorganic carbon which is converted into organic matter during the photosynthesis, and which feeds upper trophic layers. The daily primary production is estimated from satellite observations with the Antoine and Morel algorithm (1996). This algorithm modelized the potential growth in function of the light and temperature conditions, and with the chlorophyll concentration as a biomass index. The monthly area average is computed from monthly primary production weighted by the pixels size. The trend is computed from the deseasonalised time series (1998-2022), following the Vantrepotte and Mélin (2009) method. The trend estimate is not shown because the length of the time series does not allow to completely differentiate the climate trend to the natural variability of the primary production. More details are provided in the Ocean State Reports 4 (Cossarini et al. ,2020). '''CONTEXT''' Marine primary production is at the basis of the marine food web and produce about 50% of the oxygen we breath every year (Behrenfeld et al., 2001). Study primary production is of paramount importance as ocean health and fisheries are directly linked to the primary production (Pauly and Christensen, 1995, Fee et al., 2019). Changes in primary production can have consequences on biogeochemical cycles, and specially on the carbon cycle, and impact the biological carbon pump intensity, and therefore climate (Chavez et al., 2011). Despite its importance for climate and socio-economics resources, primary production measurements are scarce and do not allow a deep investigation of the primary production evolution over decades. Satellites observations and modelling can fill this gap. However, depending of their parametrisation, models can predict an increase or a decrease in primary production by the end of the century (Laufkötter et al., 2015). Primary production from satellite observations presents therefore the advantage to dispose an archive of more than two decades of global data. This archive can be assimilated in models, in addition to direct environmental analysis, to minimise models uncertainties (Gregg and Rousseaux, 2019). In the Ocean State Reports 4, primary production estimate from satellite and from modelling are compared at the scale of the Mediterranean Sea. This demonstrates the ability of such a comparison to deeply investigate physical and biogeochemical processes associated to the primary production evolution (Cossarini et al., 2020) '''CMEMS KEY FINDINGS''' Global primary production does not show specific trend and remain relatively constant over the archive 1998-2022. The temporal variability of the primary production appears to be mainly driven by the seasonal variation. However, some specific inter-annual event may induce noticeable increase or decrease in primary production, as for example in the second part of 2011. '''DOI (product):''' https://doi.org/10.48670/moi-00225
-
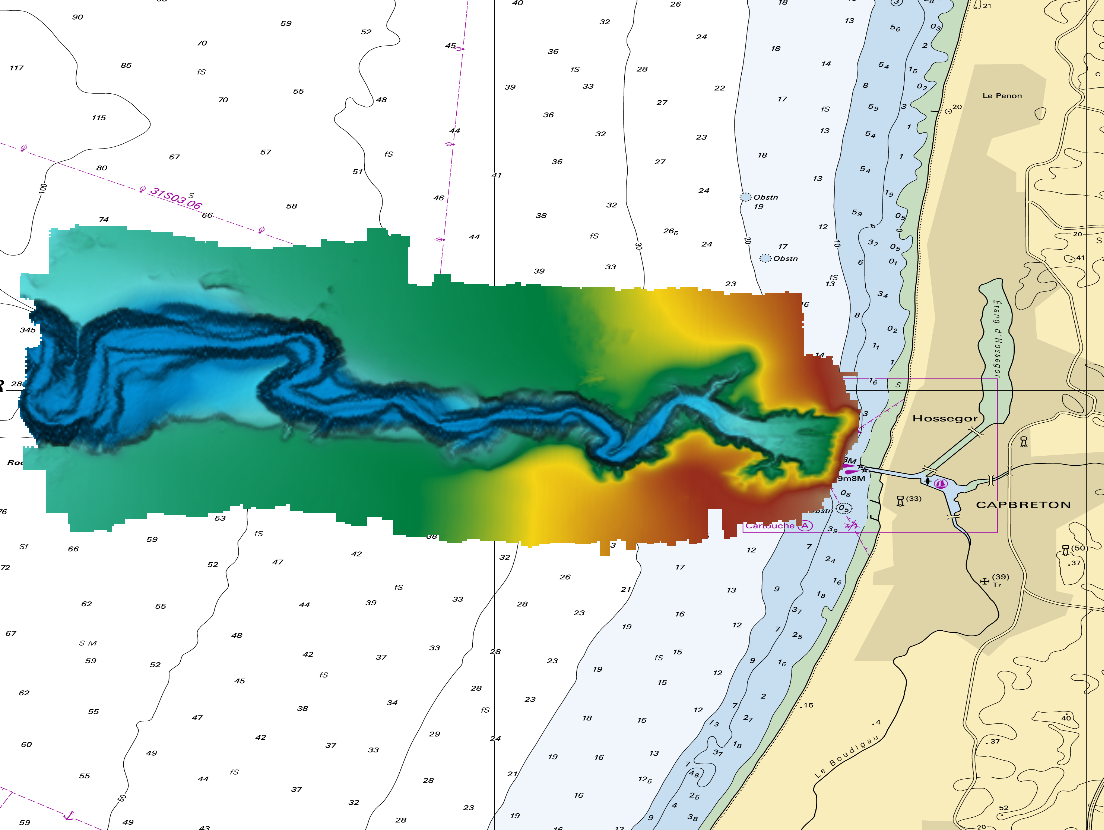
The DTM is a compilation of multibeam echosounder surveys acquired in 2013. The resolution is 1/64 arc-minutes (~30m). Surveys are located on the Capbreton Submarine Canyon (France) with depths from -4.7m to -344.9m. Depths are referenced to the Lowest Astronomical Tide and the coordinates are expressed into the WGS84 reference frame. The surveys which compose the DTM are S201306500-09 and S201306500-11. Data and metadata associated to these surveys are available on the website http://diffusion.shom.fr/pro/lots-bathy.html. The DTM is not to be used for navigation.
-

This dataset contains the high-frequency total horizontal current at 15m depth on a global grid at 1/4° resolution. It is composed by the addition of two components, the first is the Geostrophic current derived by Altimetry, from the DT-2018 CMEMS database, and the second is the unsteady-Ekman ageostrophic component forced by the wind. All the details about the algorithm and the physical content of this ageostrophy component are given in the ATBD. The data are available through HTTP and FTP; access to the data is free and open. This dataset was generated by Datlas Ocean and is distributed by Ifremer / CERSAT in the frame of the World Ocean Circulation (WOC) project funded by the European Space Agency (ESA).