 Catalogue PIGMA
Catalogue PIGMA
2021
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
Resolution
-

This map presents all layers corresponding to "Cargo handling" activities in the Atlantic area. For more information about this NACE code : https://ec.europa.eu/eurostat/ramon/nomenclatures/index.cfm?TargetUrl=DSP_NOM_DTL_VIEW&StrNom=NACE_REV2&StrLanguageCode=EN&IntPcKey=18513344&IntKey=18513464&StrLayoutCode=HIERARCHIC&IntCurrentPage=1 Indicators collected are : Number of persons employed and number of employees in full time equivalent units per NUTS 3 unit of the Atlantic Area
-

"'Short description:''' The High-Resolution Ocean Colour (HR-OC) Consortium (Brockmann Consult, Royal Belgian Institute of Natural Sciences, Flemish Institute for Technological Research) distributes Level 4 (L4) Turbidity (TUR, expressed in FNU), Solid Particulate Matter Concentration (SPM, expressed in mg/l), particulate backscattering at 443nm (BBP443, expressed in m-1) and chlorophyll-a concentration (CHL, expressed in µg/l) for the Sentinel 2/MSI sensor at 100m resolution for a 20km coastal zone. The products are delivered on a geographic lat-lon grid (EPSG:4326). BBP443, constitute the category of the 'optics' products. The BBP443 product is generated from the L3 RRS products using a quasi-analytical algorithm (Lee et al. 2002). he 'tur_tsm_chl' products include TUR, SPM and CHL. They are retrieved through the application of automated switching algorithms to the RRS spectra adapted to varying water conditions (Novoa et al. 2017). The GEOPHYSICAL product consists of the Chlorophyll-a concentration (CHL) retrieved via a multi-algorithm approach with optimized quality flagging (O'Reilly et al. 2019, Gons et al. 2005, Lavigne et al. 2021). Monthly products (P1M) are temporal aggregates of the daily L3 products. Daily products contain gaps in cloudy areas and where there is no overpass at the respective day. Aggregation collects the non-cloudy (and non-frozen) contributions to each pixel. Contributions are averaged per variable. While this does not guarantee data availability in all pixels in case of persistent clouds, it provides a more complete product compared to the sparsely filled daily products. The Monthly L4 products (P1M) are generally provided withing 4 days after the last acquisition date of the month. Daily gap filled L4 products (P1D) are generated using the DINEOF (Data Interpolating Empirical Orthogonal Functions) approach which reconstructs missing data in geophysical datasets by using a truncated Empirical Orthogonal Functions (EOF) basis in an iterative approach. DINEOF reconstructs missing data in a geophysical dataset by extracting the main patterns of temporal and spatial variability from the data. While originally designed for low resolution data products, recent research has resulted in the optimization of DINEOF to handle high resolution data provided by Sentinel-2 MSI, including cloud shadow detection (Alvera-Azcárate et al., 2021). These types of L4 products are generated and delivered one month after the respective period. '''Processing information:''' The HR-OC processing system is deployed on Creodias where Sentinel 2/MSI L1C data are available. The production control element is being hosted within the infrastructure of Brockmann Consult. The processing chain consists of: * Resampling to 60m and mosaic generation of the set of Sentinel-2 MSI L1C granules of a single overpass that cover a single UTM zone. * Application of a glint correction taking into account the detector viewing angles * Application of a coastal mask with 20km water + 20km land. The result is a L1C mosaic tile with data just in the coastal area optimized for compression. * Level 2 processing with pixel identification (IdePix), atmospheric correction (C2RCC and ACOLITE or iCOR), in-water processing and merging (HR-OC L2W processor). The result is a 60m product with the same extent as the L1C mosaic, with variables for optics, transparency, and geophysics, and with data filled in the water part of the coastal area. * invalid pixel identification takes into account corrupted (L1) pixels, clouds, cloud shadow, glint, dry-fallen intertidal flats, coastal mixed-pixels, sea ice, melting ice, floating vegetation, non-water objects, and bottom reflection. * Daily L3 aggregation merges all Level 2 mosaics of a day intersecting with a target tile. All valid water pixels are included in the 20km coastal stripes; all other values are set to NaN. There may be more than a single overpass a day, in particular in the northern regions. This step comprises resampling to the 100m target grid. * Monthly L4 aggregation combines all Level 3 products of a month and a single tile. The output is a set of 3 NetCDF datasets for (1) optics and (2) turbidity, suspended matter and chlorophyll concentration, respectively for the month. * Gap filling combines all daily products of a period and generates (partially) gap-filled daily products again. The output of gap filling are 2 datasets for (1) optics (BBP443 only) and (2) turbidity, suspended mattr and chlorophyll concentration per day. '''Description of observation methods/instruments:''' Ocean colour technique exploits the emerging electromagnetic radiation from the sea surface in different wavelengths. The spectral variability of this signal defines the so-called ocean colour which is affected by the presence of phytoplankton. '''Quality / Accuracy / Calibration information:''' A detailed description of the calibration and validation activities performed over this product can be found on the CMEMS web portal and in CMEMS-BGP_HR-QUID-009-201_to_212. '''Suitability, Expected type of users / uses:''' This product is meant for use for educational purposes and for the managing of the marine safety, marine resources, marine and coastal environment and for climate and seasonal studies. '''Dataset names: ''' *cmems_obs_oc_med_bgc_tur_spm_chl_nrt_l4-hr-mosaic_P1M-v01 *cmems_obs_oc_med_bgc_optics_nrt_l4-hr-mosaic_P1M-v01 *cmems_obs_oc_med_bgc_tur_spm_chl_nrt_l4-hr-mosaic_P1D-v01 *cmems_obs_oc_med_bgc_optics_nrt_l4-hr-mosaic_P1D-v01 '''Files format:''' *netCDF-4, CF-1.7 *INSPIRE compliant." '''DOI (product) :''' https://doi.org/10.48670/moi-00110
-

The ODIS "Catalogue of Sources" aims to be an online browsable and searchable catalogue of existing ocean related web-based sources/systems of data and information as well as products and services. It will also provide information on products and visualize the landscape (entities and their connections) of ocean data and information sources. It will contribute to the objectives of the Agenda 2030, and in particular the UN Decade for Ocean Science for Sustainable Development. The Catalogue is not an ocean database or metadata repository. The catalogue includes descriptive information such as the URL, title, description, language, point of contact, geographic scope, available technologies for machine-to-machine interaction, keywords, etc. and can be searched on many of these fields. The IODE network of NODCs has been collecting, managing and serving data for decades. This effort has yielded an extensive, but distributed and heterogeneous collection of data and information sources. Additionally, the low threshold for technical capabilities required to offer data and information over the Internet means that many of the hosted resources are not readily discoverable through NODCs, regional or international data and information systems ODIS will provide an online catalogue of (ideally) all online data/information sources (and, where possible, metadata on off-line sources as well). Many regional and international programmes and projects have developed online data/information services but there is currently no "one-stop shop" where users are offered an overview and/or common data/information discovery interface. There are currently 3090 sources (2172 are searchable) catalogued in the system.
-
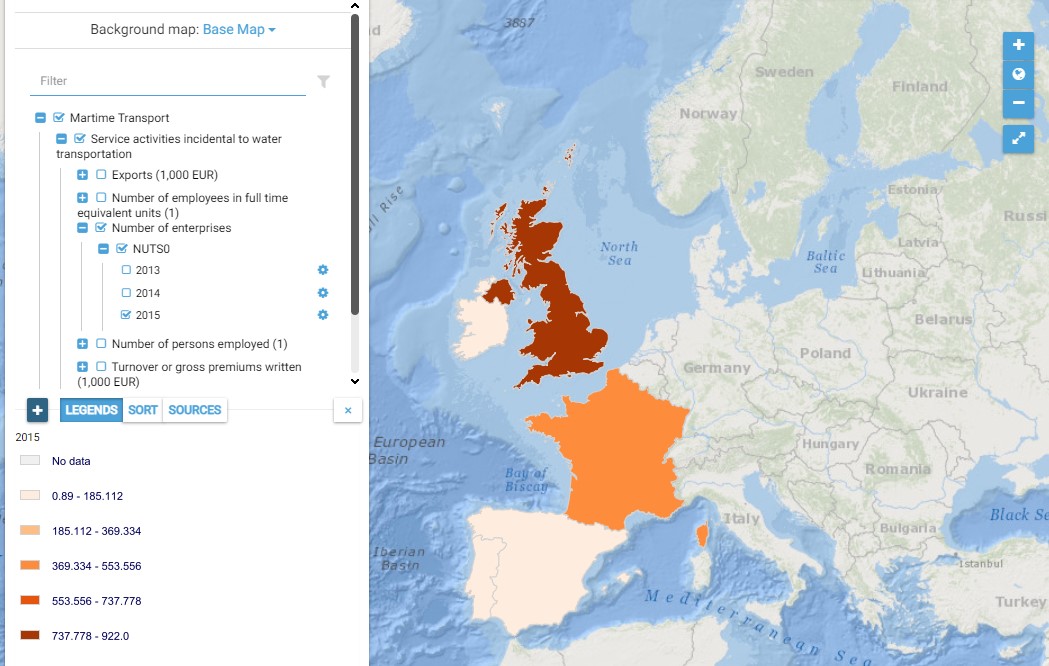
This map presents all layers corresponding to "Service activities incidental to water transportation" activities in the Atlantic area. For more information about this NACE code : https://ec.europa.eu/eurostat/ramon/nomenclatures/index.cfm?TargetUrl=DSP_NOM_DTL_VIEW&StrNom=NACE_REV2&StrLanguageCode=EN&IntPcKey=18513344&IntKey=18513404&StrLayoutCode=HIERARCHIC&IntCurrentPage=1 Indicators collected are : Business indicators per country Number of persons employed and number of employees in full time equivalent units per NUTS 3 unit of the Atlantic Area
-
L'orthophotographie de précision planimétrique de classe A (arrêté du 16 septembre 2003) et produit en RVB (couleurs : Rouge, Vert, Bleu) constitue la composante image du géostandard PCRS. Un PCRS constitue le socle commun topographique minimal de base décrivant à très grande échelle les limites apparentes de la voirie. Il est limité aux objets les plus utiles et n'aborde aucune des logiques "métiers" par ailleurs traitées chez les gestionnaires de réseaux. Le PCRS est destiné à servir de support topographique à un grand nombre d'applications requérant la meilleure précision possible. Il répond essentiellement aux exigences de la réglementation dite "anti-endommagement" ou réforme DT-DICT portant sur les travaux à proximité des réseaux, notamment sous la forme d'un fond de plan utilisable dans le cadre des échanges entre gestionnaires et exploitants. Conçu pour facilité les échanges entre les plans de type DAO et les SIG des collectivité et exploitants, les objets du PCRS gèrent peu d'attributs autres que ceux liés à la généalogie de leur acquisition, majoritairement par levé topographique.
-

This layer shows the current known extent and distribution of live hard coral cover in European waters, collated by EMODnet Seabed Habitats. The polygons portion was last updated in 2019. The points were added in Sept 2021. Lophelia pertusa and Coral gardens are both on the OSPAR List of threatened and/or declining species and habitats. The purpose was to produce a data product that would provide the best compilation of evidence for the essential ocean variable (EOV) known as Hard coral cover and composition (sub-variable: Live hard coral cover and extent), as defined by the Global Ocean Observing System (GOOS). This data product should be considered a work in progress and is not an official product.
-
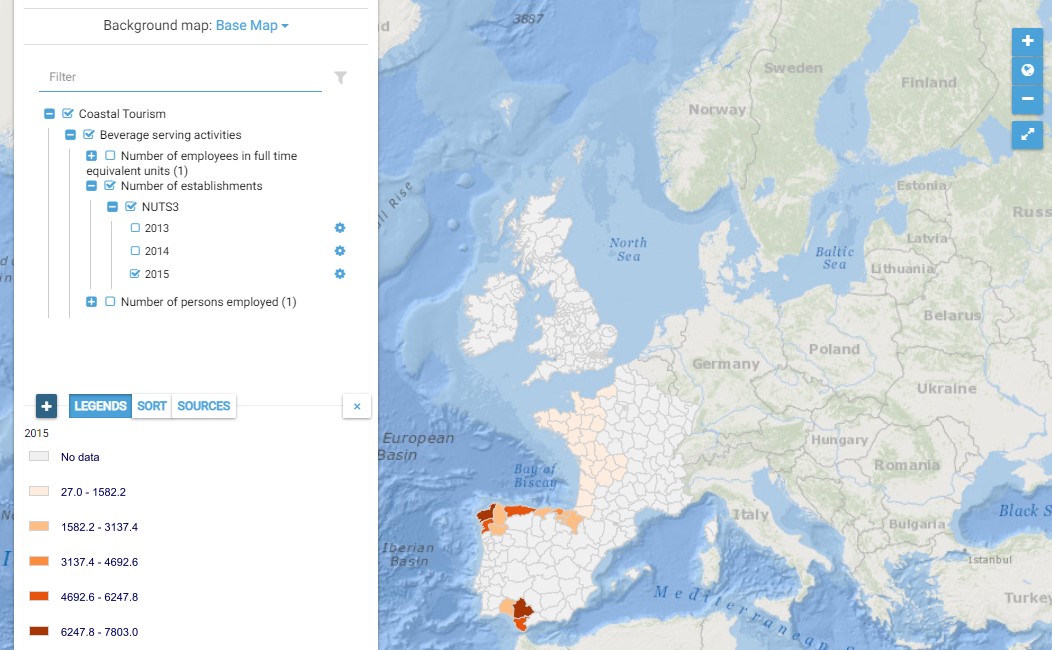
This map presents all layers corresponding to "Beverage serving activities" activities in the Atlantic area. For more information about this NACE code : https://ec.europa.eu/eurostat/ramon/nomenclatures/index.cfm?TargetUrl=DSP_NOM_DTL_VIEW&StrNom=NACE_REV2&StrLanguageCode=EN&IntPcKey=18514154&IntKey=18514184&StrLayoutCode=HIERARCHIC&IntCurrentPage=1 Indicators collected are : Number of persons employed and number of employees in full time equivalent units per NUTS 3 unit of the Atlantic Area Number of establishments per NUTS3 unit of the Atlantic Area
-

rgbif is an R package from rOpenSci that allows searching and retrieving data from GBIF. rgbif wraps R code around the GBIF API to allow you to talk to GBIF from R and access metadata, species names, and occurrences. rgbif allows you to easily: - get data for single occurrences - retrieve multiple occurences - search for taxon names - generate maps of occurences
-
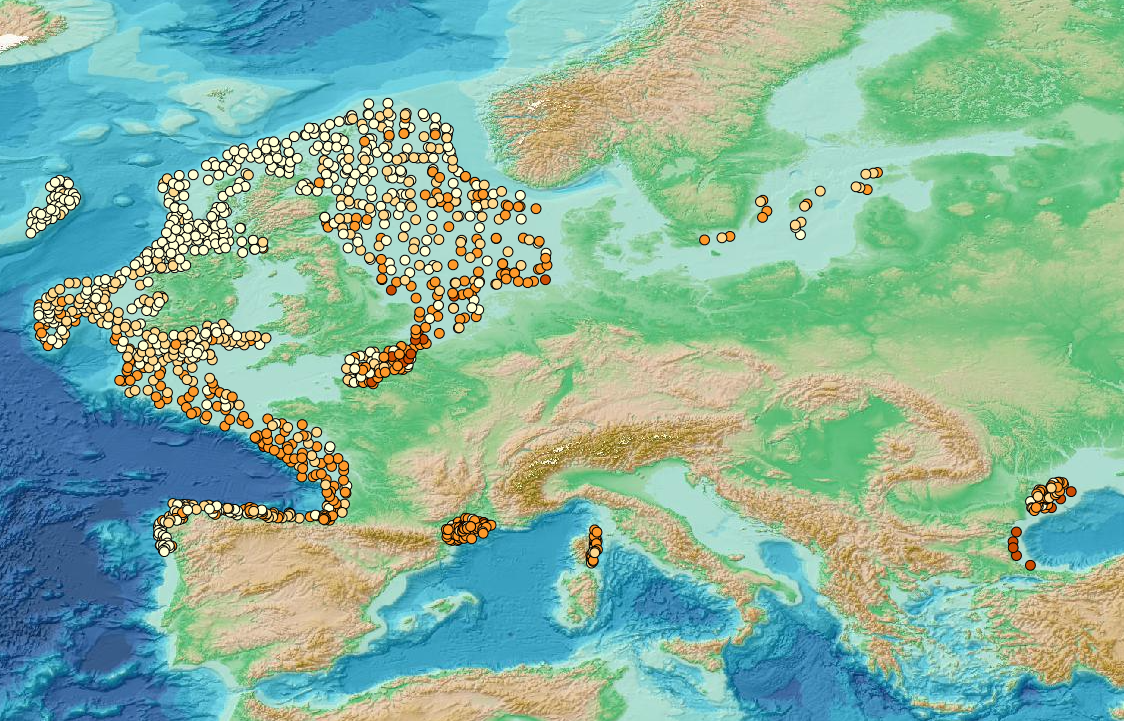
This visualization product displays the density of seafloor litter per trawl. EMODnet Chemistry included the collection of marine litter in its 3rd phase. Since the beginning of 2018, data of seafloor litter collected by international fish-trawl surveys have been gathered and processed in the EMODnet Chemistry Marine Litter Database (MLDB). The harmonization of all the data has been the most challenging task considering the heterogeneity of the data sources, sampling protocols (OSPAR and MEDITS protocols) and reference lists used on a European scale. Moreover, within the same protocol, different gear types are deployed during fishing bottom trawl surveys. In cases where the wingspread and/or number of items were unknown, data could not be used because these fields are needed to calculate the density. Data collected before 2011 are affected by this filter. When the distance reported in the data was null, it was calculated from: - the ground speed and the haul duration using this formula: Distance (km) = Haul duration (h) * Ground speed (km/h); - the trawl coordinates if the ground speed and the haul duration were not filled in. The swept area is calculated from the wingspread (which depends on the fishing gear type) and the distance trawled: Swept area (km²) = Distance (km) * Wingspread (km) Densities have been calculated on each trawl and year using the following computation: Density (number of items per km²) = ∑Number of items / Swept area (km²) Percentiles 50, 75, 95 & 99 have been calculated taking into account data for all years. More information on data processing and calculation are detailed in the document attached. Warning: the absence of data on the map doesn't necessarily mean that they don't exist, but that no information has been entered in the Marine Litter Database for this area.
-

'''This product has been archived''' For operationnal and online products, please visit https://marine.copernicus.eu '''DEFINITION''' We have derived an annual eutrophication and eutrophication indicator map for the North Atlantic Ocean using satellite-derived chlorophyll concentration. Using the satellite-derived chlorophyll products distributed in the regional North Atlantic CMEMS REP Ocean Colour dataset (OC- CCI), we derived P90 and P10 daily climatologies. The time period selected for the climatology was 1998-2017. For a given pixel, P90 and P10 were defined as dynamic thresholds such as 90% of the 1998-2017 chlorophyll values for that pixel were below the P90 value, and 10% of the chlorophyll values were below the P10 value. To minimise the effect of gaps in the data in the computation of these P90 and P10 climatological values, we imposed a threshold of 25% valid data for the daily climatology. For the 20-year 1998-2017 climatology this means that, for a given pixel and day of the year, at least 5 years must contain valid data for the resulting climatological value to be considered significant. Pixels where the minimum data requirements were met were not considered in further calculations. We compared every valid daily observation over 2020 with the corresponding daily climatology on a pixel-by-pixel basis, to determine if values were above the P90 threshold, below the P10 threshold or within the [P10, P90] range. Values above the P90 threshold or below the P10 were flagged as anomalous. The number of anomalous and total valid observations were stored during this process. We then calculated the percentage of valid anomalous observations (above/below the P90/P10 thresholds) for each pixel, to create percentile anomaly maps in terms of % days per year. Finally, we derived an annual indicator map for eutrophication levels: if 25% of the valid observations for a given pixel and year were above the P90 threshold, the pixel was flagged as eutrophic. Similarly, if 25% of the observations for a given pixel were below the P10 threshold, the pixel was flagged as oligotrophic. '''CONTEXT''' Eutrophication is the process by which an excess of nutrients – mainly phosphorus and nitrogen – in a water body leads to increased growth of plant material in an aquatic body. Anthropogenic activities, such as farming, agriculture, aquaculture and industry, are the main source of nutrient input in problem areas (Jickells, 1998; Schindler, 2006; Galloway et al., 2008). Eutrophication is an issue particularly in coastal regions and areas with restricted water flow, such as lakes and rivers (Howarth and Marino, 2006; Smith, 2003). The impact of eutrophication on aquatic ecosystems is well known: nutrient availability boosts plant growth – particularly algal blooms – resulting in a decrease in water quality (Anderson et al., 2002; Howarth et al.; 2000). This can, in turn, cause death by hypoxia of aquatic organisms (Breitburg et al., 2018), ultimately driving changes in community composition (Van Meerssche et al., 2019). Eutrophication has also been linked to changes in the pH (Cai et al., 2011, Wallace et al. 2014) and depletion of inorganic carbon in the aquatic environment (Balmer and Downing, 2011). Oligotrophication is the opposite of eutrophication, where reduction in some limiting resource leads to a decrease in photosynthesis by aquatic plants, reducing the capacity of the ecosystem to sustain the higher organisms in it. Eutrophication is one of the more long-lasting water quality problems in Europe (OSPAR ICG-EUT, 2017), and is on the forefront of most European Directives on water-protection. Efforts to reduce anthropogenically-induced pollution resulted in the implementation of the Water Framework Directive (WFD) in 2000. '''CMEMS KEY FINDINGS''' Some coastal and shelf waters, especially between 30 and 400N showed active oligotrophication flags for 2020, with some scattered offshore locations within the same latitudinal belt also showing oligotrophication. Eutrophication index is positive only for a small number of coastal locations just north of 40oN, and south of 30oN. In general, the indicator map showed very few areas with active eutrophication flags for 2019 and for 2020. The Third Integrated Report on the Eutrophication Status of the OSPAR Maritime Area (OSPAR ICG-EUT, 2017) reported an improvement from 2008 to 2017 in eutrophication status across offshore and outer coastal waters of the Greater North Sea, with a decrease in the size of coastal problem areas in Denmark, France, Germany, Ireland, Norway and the United Kingdom. Note: The key findings will be updated annually in November, in line with OMI evolutions. '''DOI (product):''' https://doi.org/10.48670/moi-00195