 Catalogue PIGMA
Catalogue PIGMA
Data
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Years
Formats
Representation types
Update frequencies
status
Scale
Resolution
-
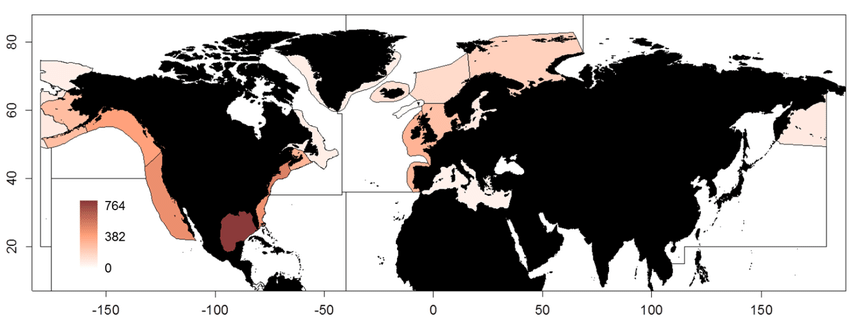
This dataset containing traits of marine fish is based on fish taxa observed during international scientific bottom-trawl surveys regularly conducted in the Northeast Atlantic, Northwest Atlantic and the Northeast Pacific. These scientific surveys target primarily demersal (bottom-dwelling) fish species, but pelagic species are also regularly recorded. The overarching aim of this dataset was to collect information on ecological traits for as many fish taxa as possible and to find area-specific trait values to account for intraspecific variation in traits, especially for widely distributed species. We collected traits for species, genera and families. The majority of trait values were sourced from FishBase (Froese and Pauly, 2019), and have been supplemented with values from the primary literature.
-
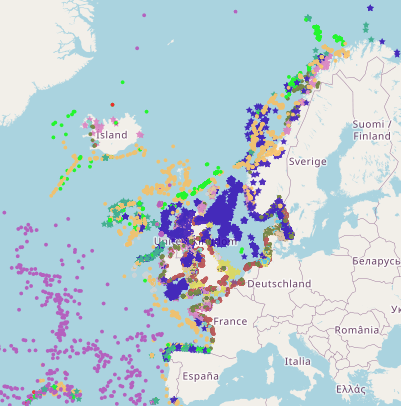
This is a compilation of OSPAR habitat point data for the northeast Atlantic submitted by OSPAR contracting parties. The compilation is coordinated by the UK's Joint Nature Conservation Committee, working with a representative from each of the OSPAR coastal contracting parties. This public dataset does not contain records relating to sensitive species (e.g. Ostrea edulis) in specific areas, or where data are restricted from public release by the owner's use limitations. This version (v2020) was published in July 2021.
-
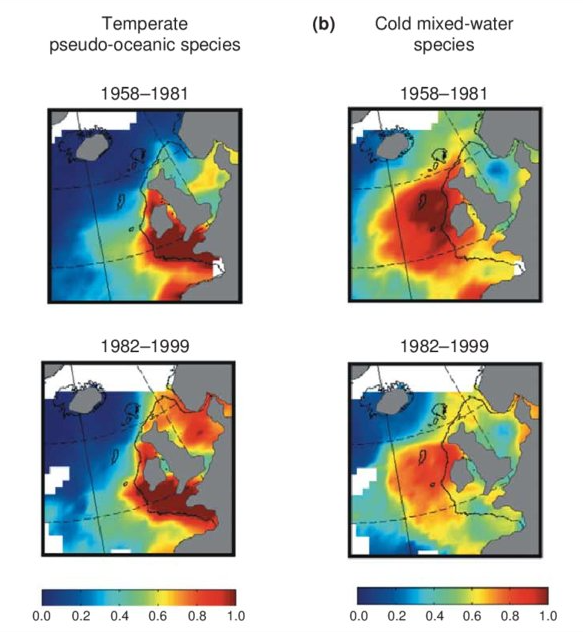
Excel file containing CPR data from Standard Areas B4,C3,C4,D3,D4,D5,E4,F4 for the plankton Calanus finmarchicus and helgolandicus, total traverse (small) copepods, total large copepods, Phytoplankton Colour Index and Cnidaria (presence denoted by a 1, absence by a zero). All taxa are from 1980, except Cnidaria which are from 2011. Dataset is in the format of sample level data, with each row being a discrete sample, with a sample being 3m3 filtered seawater, and 10nm of tow. For each row, a sample has the following information, starting at column a: Standard area of sample, sample id, latitude (decimal degrees) of sample mid point, longitude (decimal degrees) of sample midpoint, sample midpoint date and local time, year of sample, month of sample, then plankton abundance values (or PCI index or cnidaria presence/absence). All taxa have been looked for during the period this dataset spans, so zero values represent true absence.
-

NOAA High-resolution Blended Analysis of Daily SST and Ice. Data is from Sep 1981 and is on a 1/4 deg global grid.
-
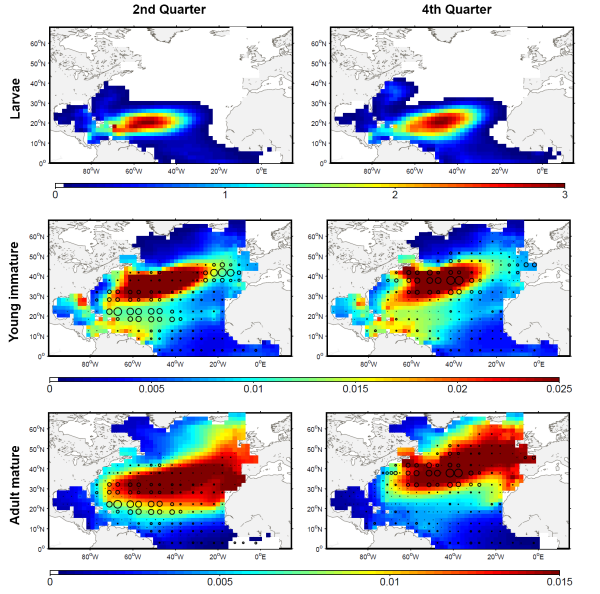
The development of the ecosystem approach and models for the management of ocean marine resources requires easy access to standard validated datasets of historical catch data for the main exploited species. They are used to measure the impact of biomass removal by fisheries and to evaluate the models skills, while the use of standard dataset facilitates models inter-comparison. North Atlantic albacore tuna is exploited all year round by longline and in summer and autumn by surface fisheries and fishery statistics compiled by the International Commission for the Conservation of Atlantic Tunas (ICCAT). Catch and effort with geographical coordinates at monthly spatial resolution of 1° or 5° squares were extracted for this species with a careful definition of fisheries and data screening. In total, thirteen fisheries were defined for the period 1956-2010, with fishing gears longline, troll, mid-water trawl and bait fishing. However, the spatialized catch effort data available in ICCAT database represent a fraction of the entire total catch. Length frequencies of catch were also extracted according to the definition of fisheries above for the period 1956-2010 with a quarterly temporal resolution and spatial resolutions varying from 1°x 1° to 10°x 20°. The resolution used to measure the fish also varies with size-bins of 1, 2 or 5 cm (Fork Length). The screening of data allowed detecting inconsistencies with a relatively large number of samples larger than 150 cm while all studies on the growth of albacore suggest that fish rarely grow up over 130 cm. Therefore, a threshold value of 130 cm has been arbitrarily fixed and all length frequency data above this value removed from the original data set.
-
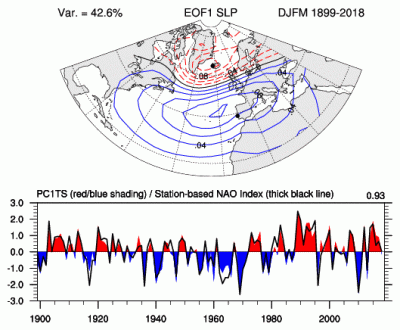
The principal component (PC)-based indices of the North Atlantic Oscillation (NAO) are the time series of the leading Empirical Orthogonal Function (EOF) of SLP anomalies over the Atlantic sector, 20°-80°N, 90°W-40°E. These indices are used to measure the NAO throughout the year, tracking the seasonal movements of the Icelandic low and Azores high. These movements are illustrated in the Figures on this page. Positive values of the NAO index are typically associated with stronger-than-average westerlies over the middle latitudes, more intense weather systems over the North Atlantic and wetter/milder weather over western Europe.
-
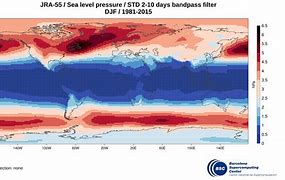
JRA55-do is a surface dataset for driving ocean-sea ice models and used in phase 2 of OMIP (OMIP-2). JRA55-do corrects the atmospheric reanalysis product JRA-55 (Kobayashi et al., 2015) using satellite and other atmospheric reanalysis products. The merits of JRA55-do are the high horizontal resolution (~55 km) and temporal interval (3 h). An assessment by Tsujino et al. (2020) implies that JRA55-do can suitably replace the current CORE/OMIP-1 dataset. This reanalysis of atmospheric variables is provided by the Japanese Meteorological Agency starting in the year 1958 and will be used to drive the coupled NEMO-ERSEM model in the hindcast configuration.
-
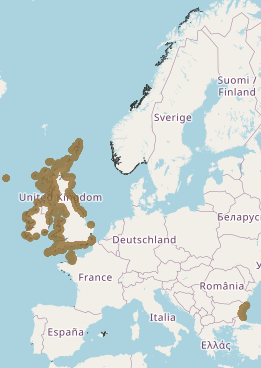
This layer shows the current known extent and distribution of macroalgal canopy in European waters, collated by EMODnet Seabed Habitats. The polygons portion was last updated in 2019. The points were added in Sept 2021. The purpose was to produce a data product that would provide the best compilation of evidence for the essential ocean variable (EOV) known as Macroalgal canopy cover and composition (sub-variable: Areal extent), as defined by the Global Ocean Observing System (GOOS). Kelp and fucoid brown algae are the dominant species that comprise macroalgal forests. This data product should be considered a work in progress and is not an official product.
-

SEAPOP (SEAbird POPulations) is a long-term monitoring and mapping programme for Norwegian seabirds that was established in 2005. The programme covers seabird populations in Norway, Svalbard and adjacent sea areas, and will provide and maintain base-line knowledge of seabirds for an improved management of this marine environment. The data analyses aim to develop further models of seabird distribution and population dynamics using different environmental parameters, and to explore the degree of covariation across different sites and species. This knowledge is urgently needed to distinguish human influences from those caused by natural variation.
-
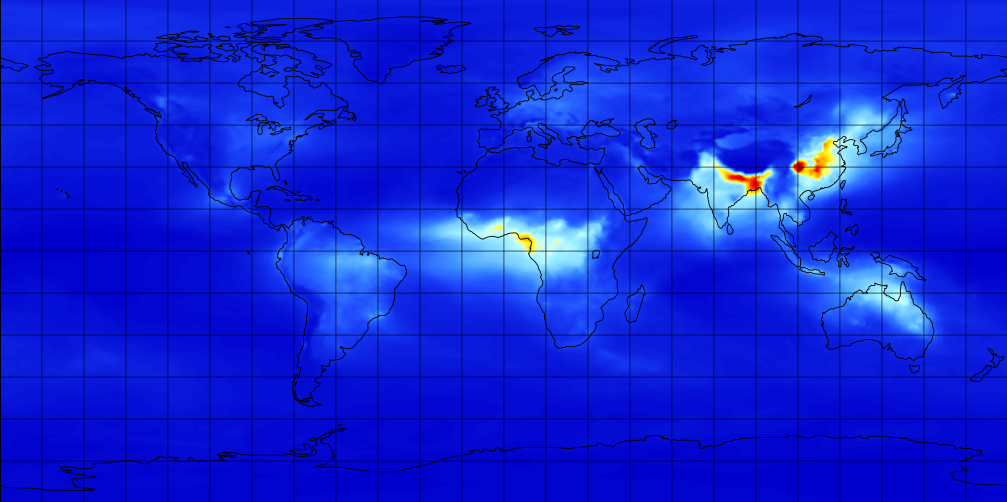
M2TMNXAER (or tavgM_2d_aer_Nx) is a time-averaged 2-dimensional monthly mean data collection in Modern-Era Retrospective analysis for Research and Applications version 2 (MERRA-2). This collection consists of assimilated aerosol diagnostics, such as column mass density of aerosol components (black carbon, dust, sea salt, sulfate, and organic carbon), surface mass concentration of aerosol components, and total extinction (and scattering ) aerosol optical thickness (AOT) at 550 nm. The total PM1.0, PM2.5, and PM10 may be derived with the formula described in the FAQs under the Documentation tab of this page. The collection also includes variance of certain parameters. MERRA-2 is the latest version of global atmospheric reanalysis for the satellite era produced by NASA Global Modeling and Assimilation Office (GMAO) using the Goddard Earth Observing System Model (GEOS) version 5.12.4. The dataset covers the period of 1980-present with the latency of ~3 weeks after the end of a month.